Jini grew from early work in Java to make distributed computing easier. It intends to make ``network devices'' and ``network computing'' into standard components of everyone's computing environment. When you buy a new piece of office computing equipment such as a desk lamp, or a new home computer appliance such as an alarm clock, it will not only carry out its ``traditional'' functions but will also join into a network of other computer devices and services. The desk lamp will turn itself off when you leave your desk, informed by sensors in your chair; the alarm clock will tell your coffee maker to switch on a few minutes before it wakes you up.
Homes, offices and factories are becoming increasingly networked. Current twisted pair wiring will remain, but will be augmented by wireless networks and networks built on your phone lines and power cables. On top of this will be an infrastructure to allow devices to communicate. TCP/IP will be a part of this, but will not be enough. There will need to be mechanisms for service discovery, for negotiation of properties, and for event signalling (``my alarm has gone off - does anyone want to know?'').
Jini supplies this higher level of interaction. This chapter gives a brief overview of the components of a Jini system and the relationships between them.
Jini is the name for a distributed computing environment, that can offer ``network plug and play''. A device or a software service can be connected to a network and announce its presence, and clients that wish to use such a service can then locate it and call it to perform tasks. Jini can be used for mobile computing tasks where a service may only be connected to a network for a short time, but it can more generally be used in any network where there is some degree of change. There are a large number of scenarios where this would be useful:
Jini is not an acronym for anything, and does not have a particular meaning. (though it gained a post hoc it gained an interpretation of ``Jini Is Not Initials''.) A Jini system or federation is a collection of clients and services all communicating by the Jini protocols. Often this will consist of applications written in Java, communicating using the Java Remote Method Invocation mechanism. Although Jini is written in pure Java, neither clients nor services are constrained to be in pure Java. They may include native code methods, act as wrappers around non-Java objects, or even be written in some other language altogether. Jini supplies a ``middleware'' layer to link services and clients from a variety of sources.
When you download a copy of ``Jini'', you get a mixture of things. Firstly, Jini is a specification of a set of middleware components. This includes an API (Application Programmer's Interface) so that you as a programmer can write services and components that make use of this middleware. Secondly, it includes an implementation (in pure Java) of the middleware, as a set of Java packages. By including these in the classpath of your client or service you can invoke the Jini middleware protocols to join in a Jini djinn. You also get source code to these packages as a bonus! Finally, Jini requires a number of ``standard'' services, and Sun gives basic implementations of each of these. These implementations are not an official part of ``Jini'', but are included to get you going. In practice, most users are finding these sufficient to do substantial work with Jini.
Jini is just one of a large number of distributed systems architectures, including industry-pervasive systems such as CORBA and DCOM. It is distinguished by being based on Java, and deriving many features purely from this Java basis. One of the later chapters discusses bridging between Jini and CORBA, as an example of linking these different distributed architectures.
There are other Java frameworks from Sun which would appear to overlap Jini, such as Enterprise Java Beans (EJBs). EJB's make it easier to build business logic servers, while Jini could be used to distribute these services in a ``network plug and play'' manner.
The reader should be aware that Jini is only one competitor in a non-empty market. What will condition the success or failure of Jini is partly the politics of the market, but also (hopefully!) the technical capabilities of Jini, and this book will deal with some of the technical issues involved in using Jini.
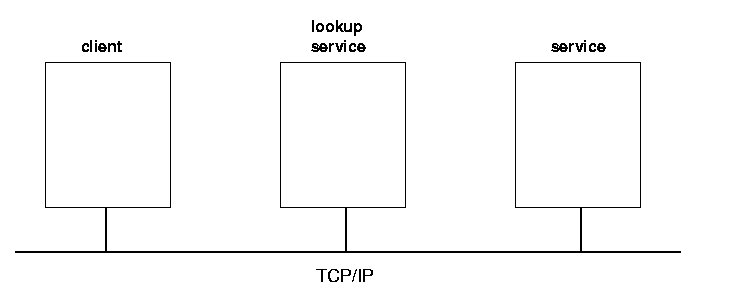
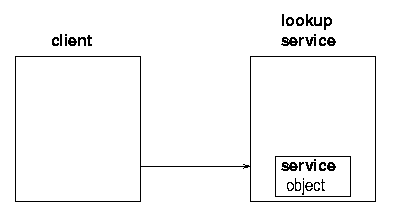
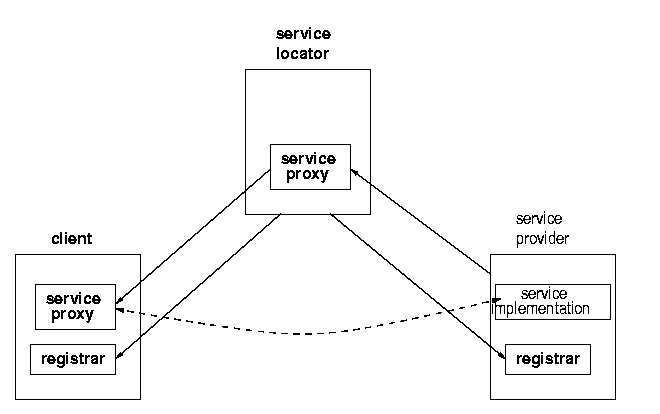
In a running Jini system, there are three main players. There is a service, such as a printer, a toaster, a marriage agency, etc. There is a client which would like to make use of this service. Thirdly, there is a lookup service (service locator) which acts as a broker/trader/locator between services and clients. There is an additional component, and that is a network connecting all three of these, and this network will generally be running TCP/IP. (The Jini specification is fairly independent of network protocol, but the only current implementation is on TCP/IP.) See figure 1.1.
Code will be moved around between these three pieces, and this is done by marshalling the objects. This involves serializing the objects in such a way that they can be moved around the network, stored in this ``freeze-dried'' form, and later reconstituted by using included information about the class files as well as instance data. This is done using Java's socket support to send and receive objects.
In addition, objects in one JVM (Java Virtual Machine) may need to invoke methods on an object in another JVM. Often this will be done using RMI (Remote Method Invocation), although the Jini specification does not require this and there are many other possibilities.
A service is a logical concept such as a blender, a chat service, a disk. It will turn out to be usually defined by a Java interface, and commonly the service itself will be identified by this interface. Each service can be implemented in many ways, by many different vendors. For example, there may be Joe's dating service, Mary's dating service or many others. What makes them the ``same'' service is that they implement the same interface; what distinguishes one from another is that each different implementation uses a different set of objects (or maybe just one object) belonging to different classes.
A service is created by a service provider. A service provider plays a number of roles:
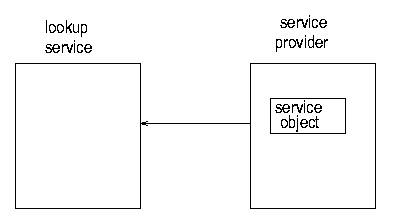
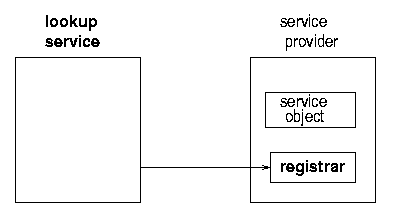
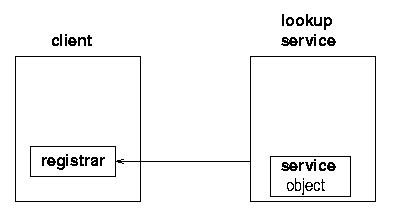
In order for the service provider to register the service object with a lookup service, the server must first find the lookup service. This can be done in two ways: if the location of the lookup service is known, then the service provider can use unicast TCP to connect directly to it. If the location is not known, the service provider will make UDP multicast requests, and lookup services may respond to these requests. Lookup services will be listening on port 4160 for both the unicast and multicast requests. (4160 is the decimal representation of hexadecimal (CAFE - BABE). Oh well, these numbers have to come from somewhere.) When the lookup service gets a request on this port, it sends an object back to the server. This object, known as a registrar, acts as a proxy to the lookup service, and runs in the service's JVM (Java Virtual Machine). Any requests that the service provider needs to make of the lookup service are made through this proxy registrar. Any suitable protocol may be used to do this, but in practice the implementations that you get of the lookup service (e.g from Sun) will probably use RMI.
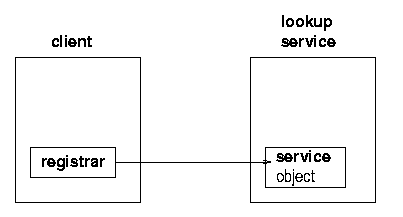
What the service provider does with the registrar is to register the service with the lookup service. This involves taking a copy of the service object, and storing it on the lookup service as in figures 1.2, 1.3 and 1.4.
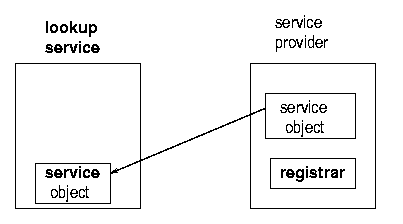
The client on the other hand, is trying to get a copy of the service into its own JVM. It goes through the same mechanism to get a registrar from the lookup service. But this time it does something different with this, which is to request the service object to be copied across to it. See figures 1.5, 1.6, 1.7, and 1.8.
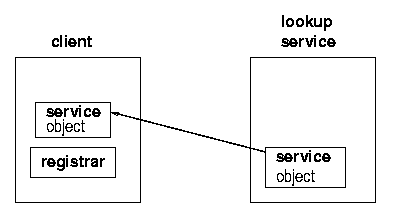
At this stage there is the original service object running back on its host. There is a copy of the service object stored in the lookup service, and there is a copy of the service object running in the client's JVM. The client can make requests of the service object running in its own JVM.
Some services can be implemented by a single object, the service object. How does this work if the service is actually a toaster, a printer, or controlling some piece of hardware? By the time the service object runs in the client's JVM, it may be a long way away from its hardware. It cannot control this remote piece of hardware all by itself. In this case, the implementation of the service must be made up of at least two objects, one running in the client and another distinct one running in the service provider.
The service object is really a proxy, which will communicate back to other objects in the service provider, probably using RMI. The proxy is the part of the service that is visible to clients, but its function will be to pass method calls back to the rest of the objects that form the total implementation of the service. There isn't a standard nomenclature for these server-side implementation objects. I shall refer to them in this book as the ``service backend'' objects.
The motivation for discussing proxies is when a service object needs to control a remote piece of hardware that is not directly accessible to the service object. However, it need not be hardware: there could be files accessible to the service provider that are not available to objects running in clients. There could be applications local to the service provider that are useful in implementing the service. Or it could simply be easier to program the service in ways that involve objects on the service provider, with the service object being just a proxy. The majority of service implementations end up with the service object being just a proxy to service backend objects, and it is quite common to see the service object being referred to as a service proxy. It is sometimes referred to a the service proxy even if the implementation doesn't use a proxy at all!
The proxy needs to communicate with other objects in the service provider. It appears we have a chicken-and-egg situation: how does the proxy find the service backend objects in its service provider? Use a Jini lookup? No, when the proxy is created it is ``primed'' with its own service provider's location so that when run it can find its own ``home''. This will appear as in figure 1.9
How is the proxy primed? This isn't specified by Jini, and can be done
in a large number of ways. For example, an RMI naming service can be used
such as rmiregistry, where the proxy is given the name of
the service. This isn't very common, as RMI proxies can be passed more
directly as returned objects from method calls,
and these can refer to ordinary RMI server objects or to
RMI activatable objects. Or the proxy can be implemented without
any direct use of RMI, and can then use an RMI exported service or some other
protocol altogether such as ftp, http or a home-grown protocol. These various
possibilities are all illustrated in later chapters.
Internally a client will look like
| Pseudocode | Where discussed |
|---|---|
prepare for discovery
|
Discovering a lookup service |
discover a lookup service
|
Discovering a lookup service |
prepare a template for lookup search
|
Entry objects and Client search |
lookup a service
|
Client search |
call the service
|
The following code is simplified from the real case, by omitting various checks
on exceptions and other conditions.
It attempts to find a FileClassifier service, and then calls the method
getMIMEType() on this service.
The full version is given in a later chapter.
We don't give detailed explanations right now, this is just to show how the
above schema translates into actual code.
public class TestUnicastFileClassifier {
public static void main(String argv[]) {
new TestUnicastFileClassifier();
}
public TestUnicastFileClassifier() {
LookupLocator lookup = null;
ServiceRegistrar registrar = null;
FileClassifier classifier = null;
// Prepare for discovery
lookup = new LookupLocator("jini://www.all_about_files.com");
// Discover a lookup service
// This uses the synchronous unicast protocol
registrar = lookup.getRegistrar();
// Prepare a template for lookup search
Class[] classes = new Class[] {FileClassifier.class};
ServiceTemplate template = new ServiceTemplate(null, classes, null);
// Lookup a service
classifier = (FileClassifier) registrar.lookup(template);
// Call the service
MIMEType type;
type = classifier.getMIMEType("file1.txt");
System.out.println("Type is " + type.toString());
}
} // TestUnicastFileClassifier
A server application will internally look like
| Pseudocode | Where discussed |
|---|---|
prepare for discovery
|
Discovering a lookup service |
discover a lookup service
|
Discovering a lookup service |
create information about a service
|
Entry objects |
export a service
|
Service registration |
renew leasing periodically
|
Leasing |
The following code is simplified from the real case, by omitting various checks
on exceptions and other conditions.
It exports an implementation of a file classifier service, as a
FileClassifierImpl object.
The full version is given in a later chapter.
We don't give detailed explanations right now, this is just to show how the
above schema translates into actual code.
public class FileClassifierServer implements DiscoveryListener {
protected LeaseRenewalManager leaseManager = new LeaseRenewalManager();
public static void main(String argv[]) {
new FileClassifierServer();
// keep server running (almost) forever to
// - allow time for locator discovery and
// - keep re-registering the lease
Thread.currentThread().sleep(Lease.FOREVER);
}
public FileClassifierServer() {
LookupDiscovery discover = null;
// Prepare for discovery - empty here
// Discover a lookup service
// This uses the asynchronous multicast protocol,
// which calls back into the discovered() method
discover = new LookupDiscovery(LookupDiscovery.ALL_GROUPS);
discover.addDiscoveryListener(this);
}
public void discovered(DiscoveryEvent evt) {
ServiceRegistrar registrar = evt.getRegistrars()[0];
// At this point we have discovered a lookup service
// Create information about a service
ServiceItem item = new ServiceItem(null,
new FileClassifierImpl(),
null);
// Export a service
ServiceRegistration reg = registrar.register(item, Lease.FOREVER);
// Renew leasing
leaseManager.renewUntil(reg.getLease(), Lease.FOREVER, this);
}
} // FileClassifierServer
Jini uses a ``service'' view of applications. This is in contrast to the simple object-oriented view of an application. Of course, a Jini ``application'' will be made up of objects, but these will be distributed out into individual services, which will communicate via their proxy objects. The Jini specification claims that in many monolithic applications there are one or more services waiting to be released, and making them into services increases their possible uses.
To see this, we can look at a ``smart file viewer''. This is an application that
will be given a filename, and based on the structure of the name will decide
what type of file it is (.rtf is Rich Text Format, .gif
is a GIF file, and so on). Using this classification it will then call up
an appropriate viewer for that type of file, such as an image viewer or document
viewer. A UML class diagram for this might look like figure
1.10
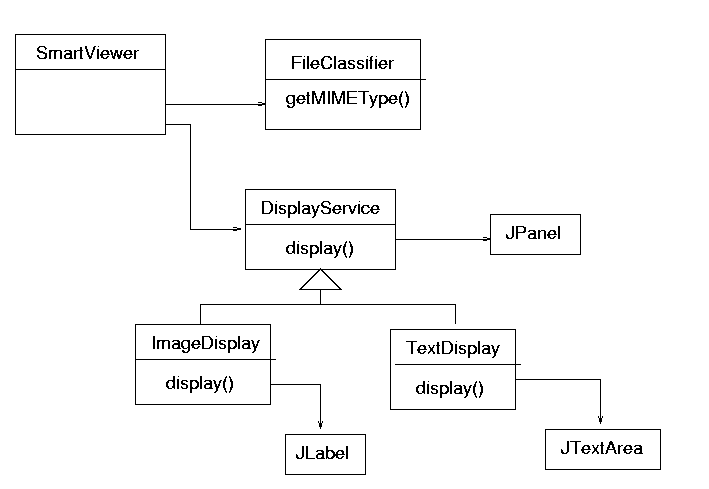
There are a number of services in this. Classifying a file into types is one (which will be used heavily in the sequel - because it is simple). This service can be used in lots of different situations, not just viewing contents. Each of the different viewer classes is another. This is not to say that every class should become a service! That would be overkill. What makes these qualify as services is that they
If the application is re-organised as a collection of services, then it could look like figure 1.11
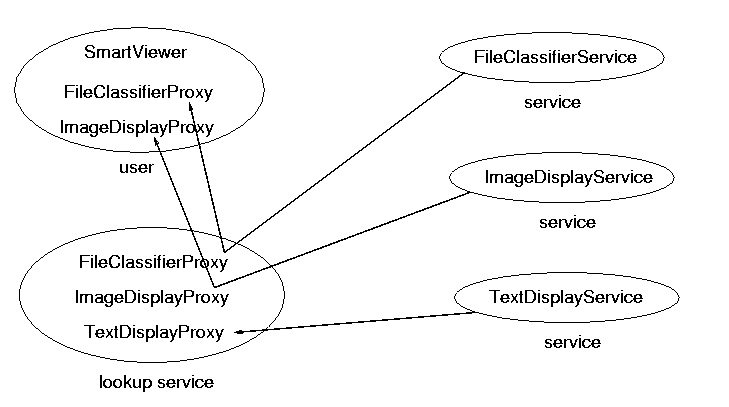
SmartViewer application finds and downloads whatever
services it needs, as it needs them.
The three components of a Jini system are clients, services and service
locators, which may run anywhere on the network. These will be implemented
using Java code running in Java Virtual Machines (JVM). The implementation
may be in pure Java but it could make use of native code by JNI
(Java Native Interface) or make external calls to other applications. Often,
each of these applications will run in its own JVM on its own computer,
though they could run on the same machine or even share the same JVM. When they run,
they will need access to Java class files, just like any other Java
application.
Each component will use the CLASSPATH environment variable
or use the classpath option to the runtime to locate the
classes it needs to run.
However, Jini also relies heavily on the ability to move objects across the network, from one JVM to another. In order to do this, particular implementations must make use of support services such as RMI daemons and HTTP (or other) servers. The particular support services required depend on implementation details, and so may vary from one Jini component to another.
A Java object running as a service has a proxy component exported to the service locators and then onto a client. It passes through one JVM in ``passive'' form and is activated ( brought to life) in the client's JVM. Essentially, a ``snapshot'' of the object's state is taken using serialization, and this snaphot is moved around. An object consists of both code and data, and it cannot be reconstituted from just its data - the code is also required. Where is the code? This is where a distributed Jini application differs from an ordinary one: the code is not likely to be on the client side. If it was required to be on the client side, then Jini would lose almost all of its flexibility because it wouldn't be possible to just add new devices and their code to a network. The class definitions are most likely on the server, or perhaps on the vendor's home Web site.
So class definitions for service proxy objects must also be downloaded,
usually from where the service came from. This could be done using a variety
of methods, but most commonly an HTTP or FTP protocol is used.
The service specifies the protocol used and also the location of the class
files using the java.rmi.server.codebase property.
The object's serialized data contains this codebase, which is used by
the client to access the class files.
If the codebase specifies an HTTP url, then there must be an HTTP server
running at that url, and the class files must be there also. This often
means one HTTP server per service, but this isn't required: a set of services
could make their class files available from a single HTTP server, and this server
could be running on a different machine to the services. This gives two sets of
class files: the set needed to run the service (specified by
CLASSPATH) and the set needed to reconstitute objects at the client
(specified by the codebase property).
For example, the mahalo service supplied by Sun as a transaction
manager uses the class files in mahalo.jar to run the service,
and the class files in mahalo-dl.jar to reconstitute the
transaction manager proxy at the client.
These files and support services are shown in
figure 1.12
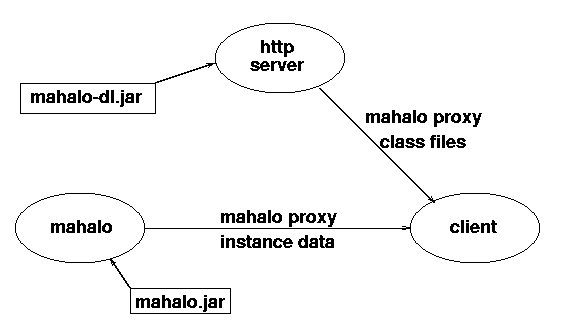
To run mahalo, the CLASSPATH must include
mahalo.jar, and to reconstitute its proxy on a client,
the codebase property must be set to mahalo-dl.jar.
A proxy service gets exported to the client. In most cases this will need to communicate
back to its host service. There are many ways to do this. One mechanism is the Java
Remote Method Invocation (RMI) system. This comes in two flavours in JDK 1.2:
the original UnicastRemoteObject and the newer Activable
class. Whereas UnicastRemoteObject requires a process to remain
alive and running, Activable objects can be stored in a passive
state and the Activation system will create a new JVM if needed when a method call
is made on the object. While passive, an activatable object will need to be
stored on some server, and this server must be one which can accept method calls
and activate the objects. Sun supply such a server, called rmid.
This is real, real obscure and deep stuff if you are new to RMI or even to the
changes it is going through. So why is it needed? Sun supply a service locator
called reggie, and this is really just another Jini service that
plays a special role. In particular, it exports proxy objects - the
registrar objects. What makes this complex is that
reggie uses Activable
in its implementation. In order to run reggie, you first have to
start an rmid server on the same machine,
and then reggie will register with it.
This isn't all downhill: running rmid has beneficial side-effects.
It maintains log files of its own state, which includes the activable objects
it is storing. So reggie can crash or terminate, and
rmid will restore it as needed. Indeed, even rmid
can crash or be terminated, and it will use its log files to restore state
so that it can still accept calls for reggie objects.
A Jini system is made up of three parts
registrar
acts as a proxy to the lookup locator, and runs on both the client
and service.
A service and a client both possess a certain structure, which is detailed in the following chapters. Services may require support from other non-Jini servers, such as an HTTp server.
If you found this chapter of value, the full book is available from APress or Amazon . There is a review of the book at Java Zone