This chapter looks at what is involved in discovering a lookup service/service locator. This is common to both services and clients.
A client locates a service by querying a lookup service (service locator). In order to do this, it must first locate such a service. On the other hand, a service must register itself with the lookup service, and in order to do so it must also first locate a service.
The initial phase of both a client and a service is thus discovering a lookup service. Such a service (or set of services) will usually have been started by some independent mechanism. The search for a lookup service can be done either by unicast or by multicast. In fact, the lookup service is just another Jini service, but it is one that is specialised to store services and pass them on to clients looking for them.
Sun supplies a lookup service called reggie as part of
the standard Jini distribution. The specification of a lookup service
is public, and in future we may expect to see other implementations
of lookup services.
There may be any number of these lookup services running in a network.
A LAN may run many lookup services to provide redundancy in case one
of them crashes. Across the internet, people may run lookup services
for a variety of reasons: a public lookup service is running on
http://www.jini.canberra.edu.au to aid people trying Jini
clients and services without needing to also set up a lookup service.
Other lookup services may act as co-ordination centres, for example
by acting as a repository of locations for all of the atomic clock
servers in the world.
Anybody can start a lookup service (depending on access permissions), but it will usually be started by an administrator, or started at boot time.
reggie requires support services to work: an HTTP server
and an RMI daemon, rmid.
If there is already an HTTP server running, this can be
used, or a new one can be started. If you don't have access to an HTTP server
(such as Apache), then there is a simple one supplied by Jini. This server
is incomplete, and is only good for downloading Java class files - it cannot
be used as a general-purpose Web server.
The Jini HTTP server is in the jar file tools.jar. This can
be started by
java -jar tools.jar
java -jar tools-jarfile [-port port-number] [-dir document-root-dir] [-trees] [-verbose]
registrar) to clients. These class files are stored in
reggie-dl.jar, so this file must be reachable from the
document root. For example, on my machine the jar file has full path
/home/jan/tmpdir/jini1_0/lib/reggie-dl.jar. I set document root
to /home/jan/tmpdir/jini1_0/lib, so the relative URL from this
server is just /reggie-dl.jar.
The other support service needed for reggie is an RMI daemon.
This is rmid, and is a part of the standard Java distribution.
This must be run on the same machine as reggie:
rmid &
rmid [-port num] [-log dir]
rmid uses log files to store its state, and they default
to being in the sub-directory log. This can be controlled.
There is a security issue with rmid on multi-user systems
such as Unix. The activation system that it supports allows anyone on
the same machine to
run programs using the user id of rmid. So you should
never run it using a sensitive user id such as
root, but instead should run it as the least privileged
user, nobody.
Once these two are running, reggie can be started:
java -jar reggie.jar ...
java -jar lookup-server-jarfile lookup-client-codebase lookup-policy-file \
output-log-dir lookup-service-group
lookup-server-jarfile will be reggie.jar or
some path to it.
lookup-client-codebase will be the url for the
reggie stub class files, using the HTTP server started earlier.
In my case, this is http://jannote.dstc.edu.au:8080/reggie-dl.jar.
Note that an absolute IP hostname must be used - you cannot use
localhost because to the reggie service
it means jannote.dstc.edu.au, but to the client
it would be a different machine altogether! The client would then fail to find
reggie-dl.jar on its own machine. Even using an abbreviated address
such as jannote would fail to be resolved if the client is
external to the local network.
lookup-policy-file controls security accesses. To get going,
set this to the path to policy.all in the Jini distribution, but
for deployment, use a less dangerous policy file. The topic of security is
discussed in its own chapter, but in brief: Jini code mobility allows code
from other sources to run within the client machine. If you trust it, then that
may be fine (but can you really trust it?). If not, then
you don't want to run it. Jini security can control this. But in the
debugging/testing phase this can cause extra complications which can make things
harder. So turn off security while testing other aspects by using a weak
security policy, but make sure to turn it back on later!
output-log-dir can be set to any (writable)
path to store the log files.
lookup-service-group can be set to the public group public.
java -jar /home/jan/tmpdir/jini1_0/lib/reggie.jar \
http://jannote.dstc.edu.au:8080/reggie-dl.jar \
/home/jan/tmpdir/jini1_0/example/lookup/policy.all \
/tmp/reggie_log public
rmid, and will be brought
back into existence whenever necessary (this is done by the new
Activation mechanism of RMI in JDK 1.2).
You only need to start reggie once, even if your machine is
switched off or rebooted. The activation daemon rmid restarts
it on an as-needed basis, as it keeps information about reggie
in its log files.
rmid is responsible for starting (or restarting) services
such as reggie. It will create a new JVM on demand, to run
the service. rmid may look after a number of services,
not just reggie, and they will all be run in their own
JVMs. In JDK 1.2 there was no difference in handling these different
JVMs. However, in JDK 1.3 the ability to set different security policies
was introduced. This topic is dealt with in detail in Chapter 12.
In JDK 1.3, starting rmid requires an extra parameter,
to set the sun.rmi.activation.execPolicy policy.
The simplest way is to set it so that rmid behaves
the same way as it did in JDK 1.2. This can be done by
rmid -J-Dsun.rmi.activation.execPolicy=none
Unicast discovery can be used when you already know the machine on which the lookup service resides, so you can ask for it directly. This is expected to be used for a lookup service that is outside of your local network, which you know the address of anyway (your home network while you are at work, given in some newsgroup or email message, or maybe even advertised on TV!).
The class LookupLocator in package
net.jini.core.discovery is used for this.
There are two constructors,
package net.jini.core.discovery;
public class LookupLocator {
LookupLocator(java.lang.String url)
throws java.net.MalformedURLException;
LookupLocator(java.lang.String host,int port);
}
jini://host/ or jini://host:port/.
If no port is given, it defaults to 4160.
The host should be a valid DNS name (such as www.jini.monash.edu.au
or an IP address (such as 137.92.11.13).
No unicast discovery is performed at this stage, though, so any
rubbish could be entered. Only a check for syntactic validity of the URL is performed.
This syntantic check is not even done for the second constructor.
The following program creates some objects with valid and invalid host/URLs. They are only checked for syntactic validity rather than existence as URLs:
package basic;
import net.jini.core.discovery.LookupLocator;
/**
* InvalidLookupLocator.java
*/
public class InvalidLookupLocator {
static public void main(String argv[]) {
new InvalidLookupLocator();
}
public InvalidLookupLocator() {
LookupLocator lookup;
// this is valid
try {
lookup = new LookupLocator("jini://localhost");
System.out.println("First lookup creation succeeded");
} catch(java.net.MalformedURLException e) {
System.err.println("First lookup failed: " + e.toString());
}
// this is probably an invalid URL,
// but the URL is syntactically okay
try {
lookup = new LookupLocator("jini://ABCDEFG.org");
System.out.println("Second lookup creation succeeded");
} catch(java.net.MalformedURLException e) {
System.err.println("Second lookup failed: " + e.toString());
}
// this IS a malformed URL, and should throw an exception
try {
lookup = new LookupLocator("A:B:C://ABCDEFG.org");
System.out.println("Third lookup creation succeeded");
} catch(java.net.MalformedURLException e) {
System.err.println("Third lookup failed: " + e.toString());
}
// this is valid, but no check is made anyway
lookup = new LookupLocator("localhost", 80);
System.out.println("Fourth lookup creation succeeded");
}
} // InvalidLookupLocator
All programs will need to be compiled using the JDK 1.2 compiler.
Jini programs will not compile or run under JDK 1.1 (any versions).
This program defines the class InvalidLookupLocator
in package basic. The source code will in the file
InvalidLookupLocator.java in the basic
subdirectory. From the parent directory, this can be compiled by
a command such as
javac basic/InvalidLookupLocator.java
basic subdirectory.
The CLASSPATH will need to include the Jini file
jini-core.jar for
compilation of the source code. When a service is run, this Jini
file will need to be in its CLASSPATH. Similarly,
when a client runs, it will also need this file in its
CLASSPATH.
The reason for this repetition is that the service and the client
are two separate applications, running in two
separate Java Virtual Machines, and quite likely will be on
two separate computers.
The InvalidLookupLocator has no additional requirements.
It does not perform any network calls, and does not require any
additional service to be running. So it can be run simply by
java -classpath ... basic.InvalidLookupLocator
A LookupLocator has methods
String getHost();
int getPort();
Search and lookup is performed by the method getRegistrar()
of the LookupLocator which returns an object of class
ServiceRegistrar.
public ServiceRegistrar getRegistrar()
throws java.io.IOException,
java.lang.ClassNotFoundException
ServiceRegistrar
is discussed in detail later.
This performs network lookup on the URL given in the LookupLocator
constructor.
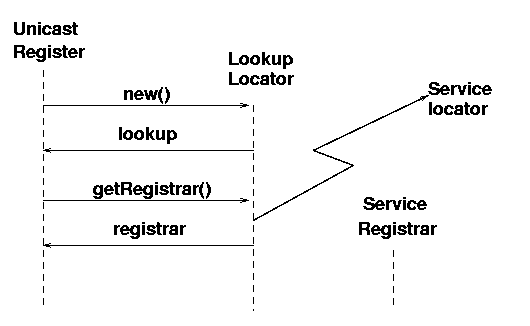
UML sequence diagrams are useful for showing the timelines of object existence
and the method calls that are made from one object to another. The timeline
reads down, and method calls and their returns read across.
A UML sequence diagram augmented with a jagged arrow showing
the network connection is shown in figure 3.1.
The UnicastRegister object makes a new() call
to create a LookupLocator and this call returns a
lookup object. The method call getRegistrar() is then
made on the lookup object, and this causes network activity.
As a result of this, a ServiceRegistrar object is created
in some manner by the lookup object,
and this is returned from the method as the registrar.
package basic;
import net.jini.core.discovery.LookupLocator;
import net.jini.core.lookup.ServiceRegistrar;
import java.rmi.RMISecurityManager;
/**
* UnicastRegistrar.java
*/
public class UnicastRegister {
static public void main(String argv[]) {
new UnicastRegister();
}
public UnicastRegister() {
LookupLocator lookup = null;
ServiceRegistrar registrar = null;
System.setSecurityManager(new RMISecurityManager());
try {
lookup = new LookupLocator("jini://jinisrv.csse.monash.edu.au");
} catch(java.net.MalformedURLException e) {
System.err.println("Lookup failed: " + e.toString());
System.exit(1);
}
try {
registrar = lookup.getRegistrar();
} catch (java.io.IOException e) {
System.err.println("Registrar search failed: " + e.toString());
System.exit(1);
} catch (java.lang.ClassNotFoundException e) {
System.err.println("Registrar search failed: " + e.toString());
System.exit(1);
}
System.out.println("Registrar found");
// the code takes separate routes from here for client or service
}
} // UnicastRegister
registrar object will be used in different ways for
clients and services: the services will use it to register themselves,
and the clients will use it to locate services.
This program might not run as is, due to security issues. If that is the case, see the first section of the chapter on Security.
The program needs to be compiled and run with
jini-code.jar in its CLASSPATH.
When run, it will attempt to connect to the service locator, so
obviously one needs to be running on the machine specified
in order for this to happen.
Otherwise, the program will throw an exception and terminate.
Here the host specified is localhost. It could,
however, be any machine accessible on the local or remote network
(as long as it is running a service locator). For example, to connect
to the service locator running on my current workstation, the parameter
to LookupLocator would be
jini://www.jini.monash.edu.au.
This program will receive a ServiceRegistrar from the
service locator. However, it does so by a simple
readObject() on a socket connected to the service
locator, and so does not need any
additional support services such as rmiregistry or
rmid. It can be run by
java -classpath ... basic.UnicastRegister
If the location of a lookup service is unknown, it is necessary to make a broadcast search for one. UDP supports a multicast mechanism which the current implementations of Jini use. Because multicast is expensive in terms of network requirements, most routers block multicast packets. This usually restricts broadcast to a local area network, although this depends on the network configuration and the time-to-live (TTL) of the multicast packets.
There may be any number of lookup services running on the network accessible to broadcast search. On a small network, such as a home network, there may be just a single lookup service, but in a large network there may be many - perhaps one or two per department. Each one of these may choose to reply to a broadcast request.
Some services may be meant for anyone to use, but some may be more restricted in applicability. For example, the Engineering Dept may wish to keep lists of services specific to that department. This may include a departmental diary service, a deparmental inventory, etc. The services themselves may be running anywhere in the organisation, but the department would like to be able to store information about them and to locate them from their own lookup service. Of course, this lookup service may be running anywhere too!
So there could be lookup services specifically for a particular group of services such as the Engineering Dept services, and others for the Publicity Dept services. Some lookup services may cater for more than one group - for example a company lookup service may want to hold information about all services running for all groups.
When a lookup service is started, it can be given a list of groups to act for as a command line parameter. A service may include such group information by giving a list of groups that it belongs too. This is an array of strings, such as
String [] groups = {"Engineering dept"};
The class
LookupDiscovery in package
net.jini.discovery is used for broadcast discovery.
There is a single constructor
LookupDiscovery(java.lang.String[] groups)
The parameter to the LookupDiscovery constructor
can take three cases
null, or LookupDiscovery.ALL_GROUPS,
means to attempt to discover all reachable lookup services
no matter which group they belong to.
This will be the normal case.
LookupDiscovery.NO_GROUPS,
means that the object is created, but no search is performed. In this
case, the method setGroups() will need to be called
in order to perform a search.
A broadcast is a multicast call across the network, expecting lookup
services to reply as they receive it. Doing so may take time, and there
will generally be an unknown number of lookup services that can reply.
To be notified of lookup services as they are discovered, the application
must register a listener with the LookupDiscovery object.
public void addDiscoveryListener(DiscoveryListener l)
DiscoveryListener
interface:
package net.jini.discovery;
public abstract interface DiscoveryListener {
public void discovered(DiscoveryEvent e);
public void discarded(DiscoveryEvent e);
}
The discovered() method is invoked whenever a lookup service
has been discovered. The API recommends that this method should return
quickly, and not make any remote calls. However, for a service it is
the natural place to register the service, and for a client it is
the natural place to ask if there is a service available and to invoke
this service. It may be better to perform these lengthy operations
in a separate thread.
There are other timing issues involved: when the
DiscoveryListener is created, the broadcast is made.
After this, a listener is added to this discovery object. What happens
if replies come in very quickly, before the listener is added?
The ``Jini Discovery Utilities Specification''
guarantees that these replies will be buffered and
delivered when a listener is added.
Conversely, no replies may come in for a long time - what is the
application supposed to do in the meantime? It cannot simply exit,
because then there would be no object to reply to! it has to be made
persistent enough to last till replies come in. One way of handling
this is if the application has a GUI interface - then it will stay
till the user dismisses it. Another possibility is that the application
may be prepared to wait for a while before giving up. In that case the main
could sleep for, say, ten seconds and then exit. This will depend on what
the application should do if no lookup service is discovered.
The discarded() method is invoked
whenever the application discards a lookup service by calling
discard() on the registrar object.
The parameter to the discovered()method of the
DiscoveryListener interface is a
DiscoveryEvent object.
package net.jini.discovery;
public Class DiscoveryEvent {
public net.jini.core.lookup.ServiceRegistrar[] getRegistrars();
}
getRegistrars()
which returns an array of ServiceRegistrar objects.
Each one of these implements the ServiceRegistrar interface,
just like the object returned from a unicast search for a lookup service.
More than one can be returned if a set of replies have come in
before the listener was registered - they are collected in an
array and returned in a single call to the listener.
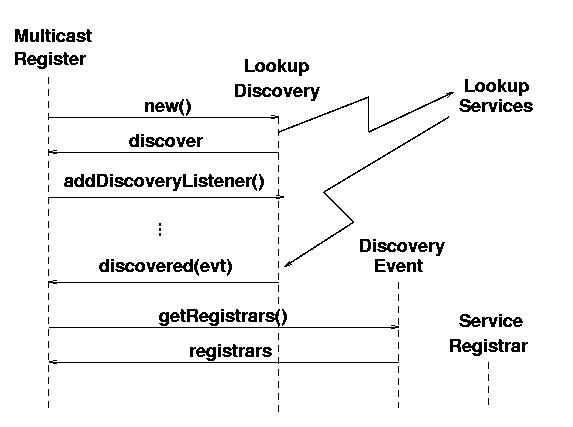
A UML sequence diagram augmented with jagged arrows showing
the network broadcast and replies is shown in figure 3.2.
In this figure, creation of a LookupDiscovery object starts
the broadcast search, and it returns the discover object.
The MulticastRegister adds itself as listener to the
discover object.
The search continues in a separate thread, and when a new lookup service
replies, the discover object invokes the discovered()
method in the MulticastRegister, passing it a newly created
DiscoveryEvent. The MulticastRegister object
can then make calls on the DiscoveryEvent such as
getRegistrars(), which will return suitable
ServiceRegistrar objects.
By this stage the program looks like
package basic;
import net.jini.discovery.LookupDiscovery;
import net.jini.discovery.DiscoveryListener;
import net.jini.discovery.DiscoveryEvent;
import net.jini.core.lookup.ServiceRegistrar;
/**
* MulticastRegister.java
*/
public class MulticastRegister implements DiscoveryListener {
static public void main(String argv[]) {
new MulticastRegister();
// stay around long enough to receive replies
try {
Thread.currentThread().sleep(10000L);
} catch(java.lang.InterruptedException e) {
// do nothing
}
}
public MulticastRegister() {
System.setSecurityManager(new java.rmi.RMISecurityManager());
LookupDiscovery discover = null;
try {
discover = new LookupDiscovery(LookupDiscovery.ALL_GROUPS);
} catch(Exception e) {
System.err.println(e.toString());
e.printStackTrace();
System.exit(1);
}
discover.addDiscoveryListener(this);
}
public void discovered(DiscoveryEvent evt) {
ServiceRegistrar[] registrars = evt.getRegistrars();
for (int n = 0; n < registrars.length; n++) {
ServiceRegistrar registrar = registrars[n];
// the code takes separate routes from here for client or service
System.out.println("found a service locator");
}
}
public void discarded(DiscoveryEvent evt) {
}
} // MulticastRegister
In the constructor we create a LookupDiscovery object,
add a DiscoveryListener and then the constructor
terminates. The main() method, having called this constructor,
promptly goes to sleep. What is going on here? The constructor to
LookupDiscovery actually starts up a
number of threads, to broadcast the service and to listen for replies.
(See the chapter on Architecture).
When replies come in, the listener thread will call the discovered()
method of the MulticastRegister. However, these threads are
daemon threads. Java has two types of threads:
daemon and user threads, and at least one user thread must be running or the
application will terminate. All these other threads are not enough to
keep the application alive, and it keep a user thread running in order
to continue to exist.
The sleep() ensures that a user thread continues to run, even though
it apparently does nothing! This will keep the application alive so that
the daemon threads (running in the ``background'') can discover some lookup
locators. Ten seconds (10,000 milliseconds) is long enough for that.
To stay alive after this ten seconds expires will depend
on either increasing the sleep time or creating another user thread in the
discovered() method. Later in this book, use is made in ``leasing''
of a useful constant Lease.FOREVER. While the ``leasing'' system
understands a special meaning for this constant, the standard Java
sleep() merely uses its value Long.MAX_VALUE
and just sleeps for a lengthy period.
I have placed the sleep() in the main() method.
It is perfectly reasonable to place it in the application constructor, and some
examples do this. However, it looks a bit strange there, so I prefer this
placement. Note that although the constructor to
MulticastRegister will have terminated without
us assigning its object reference, a live reference has been passed into the
discover object as a DiscoveryListener and it will
keep the reference alive in its own daemon threads. This means that the
application object will still exist for its discovered()
method to be called.
Any other method that results in a user thread continuing to exist will do just as well. For example, a client that has an AWT or Swing user interface will stay alive because there are many user threads created by any of these GUI objects.
For services, which typically will not have a GUI interface running,
another simple way is to create an object and then wait for another thread
to notify() it. Since nothing will, the thread (and hence the
application) stays alive. Essentially, this is an unsatisfied wait that will
never terminate - usually an erroneous thing to do, but here it is deliberate.
Object keepAlive = new Object();
synchronized(keepAlive) {
try {
keepAlive.wait();
} catch(InterruptedException e) {
// do nothing
}
}
sleep() which will terminate
eventually.
The program needs to be compiled and run with jini-core.jar
and jini-ext.jar in its CLASSPATH.
The extra jar file is needed as it contains the class files from the
net.jini.discovery package.
When run, the program will attempt to find all service locators that it
can. If there are none, it will find none - pretty boring.
So one or more should be set running in the near network or on the
local machine.
This program will receive ServiceRegistrar's from the
service locators. However, it does so by a simple
readObject() on a socket connected to a service
locator, and so does not need any
additional support services such as rmiregistry.
Services and clients search for lookup locators using the multicast protocol, by sending out packets as UDP datagrams. It makes announcements on UDP 224.0.1.84 on port 4160. How far do these announcements reach? This is controlled by two things:
LookupDiscovery sets the TTL to be 15.
Common network administrative settings restrict such packets to the local network.
However, the TTL may be changed by giving the system property
net.jini.discovery.ttl a different value.
But be careful about setting this:
many people will get irate if you flood the
networks with multicast packets.
The ServiceRegistrar is an abstract class which is
implemented by each lookup service. The actual details of this
implementation are not relevant here. The role
of a ServiceRegistrar is to act as a proxy
for the lookup service. This proxy runs in the application,
which may be a service or a client.
This is the first object that is moved from one Java process to another
in Jini. It is shipped from the lookup service to the application
looking for the lookup service, using a socket connection.
From then it runs as an
object in the application's address space, and the application makes
normal method calls to it. When needed, it communicates back to its
lookup service. The implementation used by Sun's reggie
uses RMI to communicate, but the application does not need to know
this, and anyway, it could be done in different ways.
This proxy object should not cache any information on the application side,
but get ``live'' information from the lookup service as needed.
The implementation of the lookup service supplied by Sun does exactly
this.
This object has two major methods, one used by a service attempting to register
public ServiceRegistration register(ServiceItem item,
long leaseDuration)
throws java.rmi.RemoteException
public java.lang.Object lookup(ServiceTemplate tmpl)
throws java.rmi.RemoteException;
public ServiceMatches lookup(ServiceTemplate tmpl,
int maxMatches)
throws java.rmi.RemoteException;
A service provider will register a service object (that is, an instance of a class),
and a set of attributes for that object. For example, a printer
may specify that it can handle Postscript documents, or a toaster that
it can deal with frozen slices of bread. The service provider may register
a singleton object that completely implements the service,
but more likely it will register a service proxy that will communicate
back to other objects in the service provider.
Note carefully: the registered object will be shipped around
the network. When it finally gets to run, it may be a long way away from
where it was originally created. It will have been created
in the service's JVM, transferred to the lookup locator by
register() and then to the client's JVM by
lookup().
A client is trying to find a service, using some properties of the
service that it knows about. Whereas the service can export a live
object, the client cannot use a service object as a property -
because then it would already have the thing, and wouldn't need
to try to find one! What it can do is to use a class
object, and try to find if there are any instances of this
class lying around in service locators.
As discussed later in Client Search,
it is best if the client asks for an interface class
object.
In addition to this class specification, the client may specify a set of
attribute values that it requires from the service.
The next step is to look at the possible forms of attribute values,
and how matching will be performed. This is done using Jini
Entry objects.
The simplest services, and the least demanding clients, will not
require any attributes: the Entry[] array will be
null. You may wish to skip ahead to
service registration or to
client search
and come back to entries later.
The ServiceRegistrar is returned after a successful
discovery has been made. This object has a number of methods that
will return useful information about the lookup service itself.
So in addition to using this object to register a service or lookup
a service, you can use it to find out about the lookup locator.
The major methods are
String[] getGroups();;
LookupLocator getLocator();
ServiceID getServiceID();
getGroups() will return a list of the groups
that the locator is a member of.
The second method,
getLocator() is more interesting. This is exactly the
same object as is used in the unicast lookup, but now its fields
are filled in by the discovery process. So you can find which host
the locator is running on, and its hostname by
registrar.getLocator().getHost();
public void discovered(DiscoveryEvent evt) {
ServiceRegistrar[] registrars = evt.getRegistrars();
for (int n = 0; n < registrars.length; n++) {
ServiceRegistrar registrar = registrars[n];
System.out.println("Service locator at " +
registrar.getLocator().getHost());
}
}
The third method getServiceID() is unlikely to be
of much use to you. In general, service ID's are used to give a globally
identifier for the service (no different services should have the same ID),
and a service should have the same ID with all service locators. However,
this is the service ID of the lookup service, not of any services
registered with it.
Both services and clients need to find lookup services. Discovering a lookup service may be done using unicast or multicast protocols. Unicast discovery is a synchronous mechanism. Multicast discovery is an asynchronous mechanism that requires use of a listener to respond when a new service locator is discovered.
When a service locator is discovered, it sends a
ServiceRegistrar object to run in the
client or service. This acts as a proxy for the locator.
This object may be queried for information, such as
the host the service locator is on.
If you found this chapter of value, the full book is available from APress or Amazon . There is a review of the book at Java Zone