Generic Directory Operations
Contents
Structure
Create
Delete
Opendir
Readdir
Add a file
Remove a file
Change dir
Adding files to a directory
Locating a file
Directories impose a structure onto the file system, so that it is not just
a ``collection of files''. This is needed because a non-trivial system will
have lots of files. A directory maintains information about other files in
the file system.
For example, the PC server on drive D: has over 10,00 files on it.
The file system may be flat with just one directory.
CP/M and early MSDOS had
this structure.
A more common system is a hierarchical tree of directories and files, such
as modern MSDOS.
A variation on this is a directed acyclic graph (like a tree but a node can
have more than one parent). This is used by Unix, where one file an be ``linked''
to another so that the one file has two or more file names.
Directory operations
Directories have an internal structure, unlike a general file that is just
a sequence of bytes. It is more likely to be organised as a sequence of records
of some kind. The allowable operations must take this into account.
- create
- delete
- opendir
- closedir
- readdir
- rename
- add
- link (add a file to the dir)
- unlink (remove a file from the dir)
- change dir
- find current dir
When a directory is created, a file is made with a particular record
structure. There are usually two initial records in this file, one for the
parent directory, one for the current directory. So a directory file
contains information about about where it's parent is (for traveral
upwards) and also where it is (so it can be located for operations
such as ls .).
Usually directories cannot be deleted if they still contain files
other than `.' and `..'. If they were, files would exist without a means
of accessing them. Usually any files in a directory must be removed first.
A directory is a file and can opened for reading or writing.
However, since it has a special structure, there are usally special
commands to open it
Rading a directory should be done in terms of the records it contains
rather than as a set of bytes.
Adding a file to a directory requires creating a new directory record
and adding it to the directory (treating it as a file). If the file is new,
the file system may also create file information space for it, such as an
inode.
Removing a file means that its entry must be removed from the directory.
If the file is no longer referenced, it's content may also be removed from
the file system. If it is still referenced, then this cannot happen.
A file can be referenced by multiple names in Unix, so it can only be removed
after all its names have been deleted.
A file that is still open by a process is in use, and cannot be removed
till all processes have finished with it.
A user process begins in a particular directory. It should be able to
navigate the directory structure using a change dir command.
If each process has its own current directory (Unix), then this will
just change the directory of the process. If there is a single current
directory (MSDOS) then changing the directory will be global.
When a directory is created it will be empty except for its parent and maybe
itself. The directory tree can be traversed up and down.
When a file is created (eg by creat in Unix)
an entry is made for the new file in the directory.
In the MSDOS file system, directory entries are 32-byte records.
These hold the filename, the extension,
the attributes, the date of last modification and the first block and the file
size. All the principal information about the file is held in this directory

In Unix, all that kind of information is held in the inode. The directory just
holds the name of the file and the inode number.
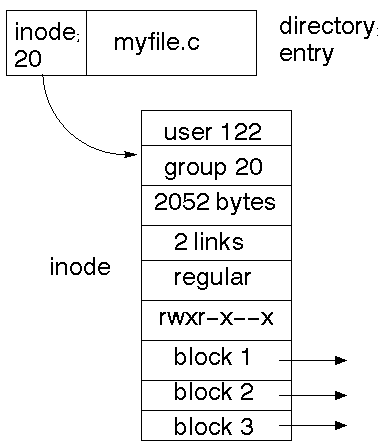
The inode method allows multiple links to the same file, as the directories
just hold the different file names and the same inode number. A ``link count''
within the inode keeps track of how many filenames a file has. When this count
drops down to zero, the file is removed.
When a file needs to be accessed, say when it is opened for reading, its blocks
on disk have to be found. Say the file is /usr/jan/file1. In Unix, the root
directory is located at a fixed place on the disk. This directory is then read
for the entry ``usr''. When it is found, its inode is known. From the inode,
the location on disk of the directory is found. This is then read looking for
the entry for ``jan''. When it is found its inode is given. From there the
directory on disk can be found, and read for the file ``file1''. When this
is found, its inode is known and the file blocks are finally located.
 Program Development using Unix Home
Program Development using Unix Home
Jan Newmarch (http://jan.newmarch.name)
jan@newmarch.name
Copyright © Jan Newmarch
Last modified: Wed Nov 19 17:51:38 EST 1997