There are a number of middleware systems that have appeared recently, such as Jini, Web services, Napster, GNUTella and JXTA. This paper gives a review of some of the technical features of these systems, including implications for network traffic.
Most users of the Internet believe that it is called the Web, and know little of its history, background or any of its technical issues. Recently DETYA (Commonwealth Department of Education, Training and Youth Affairs) issued a questionnaire to universities to investigate their use of "Web services" [sic] such as email, telnet and ftp.
Against this background, any new services that are internet based will be given a confusing and often inaccurate reception, in particular as to how they will form YAR (Yet Another Revolution). The last few years have seen a number of new internet protocols, such as Jini [1], Web services [2-4] and a variety of peer-to-peer systems including Napster [5], Gnutella [6] and JXTA [7]. The hype often obscures the actual technical content of these systems, and how their use will impact on network traffic.
This paper looks at a number of the newer protocols, and examines them for issues such as
Lookup is the mechanism whereby you find a new service by querying a known directory or agent. No search is performed by the seeker, as any searching is performed by the directory as it searches its own databases. There are many example of lookup systems on the internet. The Domain Naming Service is the best known and most widely used, but any directory service such as LDAP, or naming service such as a CORBA Naming service or Java RMI Naming service act in this manner.
Lookup directories/agents act as search mechanism for a relatively static set of services. For example, DNS is usually configured by static files that change only occasionally (for more dynamic networks, DHCP may be preferred). CORBA and Java RMI Naming services are intended for reasonably long lived services, even though there is a dynamic element in that the services register with the naming service rather than being read from static files.
Discovery is the mechanism for more dynamic systems in which there may be much more change. Services or service providers may come and go, and which services are available at any time is volatile.
These definitions are not exact, but are good enough to draw some conclusions from. A lookup mechanism usually runs from a well-known location, and if it becomes popular enough will become a single point of congestion or failure. Discovery systems may be able to avoid these dependencies on single points of access. Conversely, they have the potential to generate a large amount of traffic between peers.
When you try to find a service, some representation of this service must be given. This may be a string describing the service, an object interface for the service, etc. The matching may be exact, or may allow some degree of pattern matching.
Exact searches are much cheaper to implement than searches involving patterns. In a system with any centralised searching, pattern matching can result in degradation of performance of this central point, resulting in overall degradation of system performance.
Once a service is located, it can be invoked. There will be a mechanism to do this which varies according to the system. This mechanism may be language dependent or independent.
Jini is a Java-specific discovery system. It allows Java clients to discover Java services and call methods on these services. The early publicity about Jini claimed that it would be able to bring hardware into the network as Jini services, so that printers, VCRs, airconditioning systems, etc would be Jini-aware. This has not happened, largely because Java in its standard form is memory hungry, and those working on reduced memory versions of Java have not yet put in required support for Jini.
Where Jini has been successful is in building distributed software systems such as travel agent services, and management of distributed electricity supply systems.
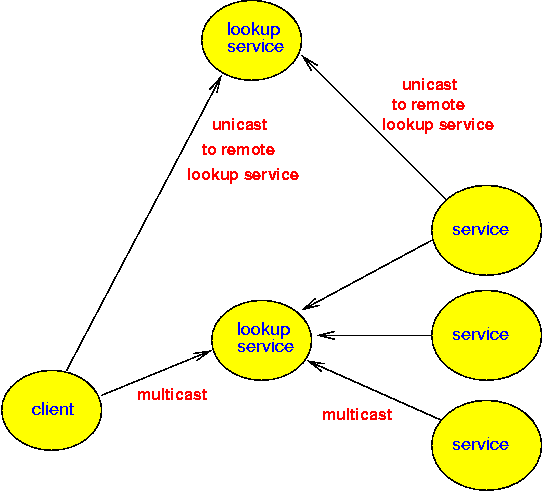
Jini uses a "directory" of services called a LookUp Service (LUS). This is dynamically populated by services registering with it. There can be many lookup services, either locally or remotely. A lookup service is a service itself, and so in principle can be federated with other lookup services to form a global system. To my knowledge, no-one is doing this yet, so lookup services tend to look after local services rather than remote ones.
Jini has both lookup and discovery systems. In order to find a lookup service, multicast can be made to discover the lookup service. Typically, multicast is restricted to the local network, so this form of discovery is limited to the local network. For lookup services outside of multicast scope, unicast lookup can be made to known addresses. There are very few publically known lookup services at present, and these are little used.
The search for a Jini service is primarily based on object class matching: a client looks for a service using a Java interface, and any service that implements that interface will return a match. This is a type-safe system, and is based on the use of Java throughout. Jini also allows matching on additional attributes, but this is based on either exact or complete wildcard matching - no partial matching is allowed. For example, a search can be made for a 24ppm printer, or for a printer of any speed. But boolean matches such as "printer faster than 24ppm" are not allowed. This reduces overheads in the lookup service, in order that a lookup service can scale to handle thousands of services. If you want sophisticated pattern matching, then Jini allows you to define a new service just to do this pattern matching.
A service is delivered as a Java object to a client requesting the service. Ordinary Java method calls are made on the service. There are many possible implementations of the service
Jini uses multicast to discover lookup services. It obeys conventions about TTL (time to live) so that multicast packets are usually restricted to the local network. While it is possible to change the TTL, most Jini services are well-behaved, and are looking at federating lookup services in order to access remote services (much like CORBA Traders can federate).
Jini uses leasing as the main mechanism for ensuring that knowledge about Jini services is reasonably up-to-date. When a service registers with a lookup service then it is granted a lease on this registration. Typically the lease lasts for five minutes, after which it has to be renewed. Leases can be used by services to clients, so that renewals can be forced to take place. The use of leases ensures that the state of the system is only about five minutes out-of-date (at worst). The traffic caused by this is fairly minor.
The other mechanism used by Jini to ensure a flexible system is the use of exceptions on failure. A network failure, a service that has died, etc, will generate Java exceptions. These can be caught by the requesting client, so that it can be robust and not be brought down itself by failures in the network.
Once a lookup service has been located by multicast, a unicast connection is made to it on port 4160. This port is also used for direct unicast connections. If this port is open then connections to lookup services can be made. However, the service may be implemented as an RMI service. RMI services will use a random port above 1024, and these will often be closed for security. It is possible to piggy-back RMI over HTTP port 80, but this is slower than using the native RMI protocol.
One complicating factor for Jini is the complexity of the environment in which it must run. This is caused by two factors:
One of the latest "revolutions" to hit the Web world is "web services". These are internet services accessible using protocols such as HTTP. They are promised to allow agents to perform the same kind of browsing that humans do but without the need for gaudy user interfaces, and in a much more precise manner using machine-readable XML instead of HTML.
SOAP [9], WSDL [10] and UDDI [11] are the technologies behind web services. Web services allow applications and agents to browse the Web on behalf of users. So instead of a user navigating HTML screens, an agent can connect to services on the Web and interact with them directly without the distraction of presentation elements.
SOAP is "Simple Object Access Protocol". It is "a lightweight protocol for exchange of information in a decentralized, distributed environment. It is an XML based protocol..." WSDL and UDDI are higher levels built above SOAP to supply extra functionality.
Basically, SOAP/WSDL/UDDI is the latest in RPC technologies. It is the first open standard RPC supported by Microsoft (although DCOM was based on DCE), and is being developed by Microsoft, IBM and Artima.
Here is what SOAP isn't:
The current state (August 2001) of this RPC mechanism is
| RPC requirement | SOAP |
|---|---|
| data types | defined by SOAP/XML standard data types |
| wire format for data | defined by SOAP using XML |
| wire format for messages | defined by SOAP over HTTP |
| an IDL | defined by WSDL |
| generation of client stubs | vendor specific |
| generation of server stubs | vendor specific |
| linking implementation | vendor specific |
The different levels are
| SOAP | wire format |
| WSDL | service specification |
| UDDI | service discovery |
UDDI directories are at well-known locations, such as XServices [12]. Clients presently locate these using unicast to these known addresses.
UDDI claims it allows service discovery. In the terms we are using the phrase, it is just lookup, not discovery. Services have to register with a UDDI registry at a known location, and clients look up their entries at these locations. Services can publish information to the registry and remove it or modify it. However, there is no leasing mechanism, so that if a service dies then stale entries will not be removed from the registry.
Each UDDI server contains a registry that can be searched for "white page" (name, address, etc) "green page" (technical information about the service) or "yellow page" (business information) entries. The technical information can be a WSDL document. The IBM implementation of a UDDI server allows wildcard searches on things like company name. When a service is found, an XML document which could contain a WSDL document is returned to the requester.
A WSDL document includes information about the location of the service, so once a service has been looked up, it can be contacted.
The WSDL description of a service is an XML document that includes information about the procedures that can be called on the service, including the parameter types and return types. It is not necessary for the client to be aware of the service description beforehand, as it can get this from the WSDL document. The client makes a SOAP call which is language independent.
Interaction between a client and a UDDI server is standard client/server using TCP. The client has foreknowledge of the server location so just connects to it. Once a search has been performed on the UDDI server a direct connection can be made to the service on port 80 to make SOAP calls. There are no particular overheads, but the UDDI server make become a bottleneck if heavily used.
Napster is a protocol for sharing MP3 files between users. This is the most visible of the recent peer-to-peer (P2P) systems. Because it involves transfer of MP3 files it has attracted attention for two reasons:
P2P models differ from client-server models in that each node is capable of acting either as a client or as a server. For Napster, this means that each node can act either as a consumer of MP3 files or as a source of MP3 files.
The napster protocol uses a central registry [13]. All services
add their files to this registry. All clients query this registry.
This is similar to the Web services model, with one proviso:
there is only one Napster, at a fixed address www.napster.com.
So directory discovery is trivial.
The Opennap project [14] can be used to establish your own napster server, but of course, it has to be advertised in some way before others can use it. Just like UDDI registries, this advertisement is by some other mechanism, such as journal articles, web pages, etc. The likelihood of other napster servers gaining widespread use is probably small given the legal issues surrounding Napster.com
The napster idea of a service is an MP3 files. Clients can make queries by filename on the napster registry, and are returned the names of nodes holding these files. With Napster, the files stay on the client machine, never passing through the server. The server provides the ability to search for particular files and initiate a direct transfer between the clients.
The Napster server is a potential bottleneck for requests. The size of the MP3 files traded is a more serious issue and can consume a large part of network bandwidth.
Gnutella is a fully-distributed information-sharing technology. Gnutella client software is basically a mini search engine and file serving system in one. When you search for something on the Gnutella Network, that search is transmitted to everyone in your Gnutella Network "horizon". If anyone had anything matching your search, it will respond to you.
Because GNUtella does not use a centralised directory, when you get a search hit, it's virtually guaranteed to be there. No stale links or irrelevant hits.
Gnutella is a peer-to-peer system, in which every client on the GnutellaNet is also a server, so you not only can find stuff, but you can also make things available for the benefit of others.
Once a peer has connected successfully to the network, it communicates with other peers by sending and receiving Gnutella protocol descriptors. Pings and queries used to discover hosts and files, respectively, are broadcast; other message types, including responses, are routed. A peer uses "Ping" to probe hosts on the network.The other peer will forward incoming Ping and Query descriptors to all of its directly connected peers, except the one that delivered the incoming Ping or Query. Pong is the response to a Ping. Includes the address of a connected Gnutella servent (Gnutella uses the word "servent" for peers) and information regarding the amount of files and their sizes it is sharing on the network.
while the protocol is designed for a user to set up connections with his "friends", there is no infrastructure in place for finding new friends. Instead, the Gnutella site offers a "default" set of friends with which users can start. Most users will never change this file if the service is functional. This means that the actual network tends to be a hierarchical system.
A query is the primary mechanism for searching the distributed network. A servent receiving a Query descriptor will respond with a QueryHit if a match is found against its local data set.
Push is used by a peer which is behind a firewall. The servent may, for example, be behind a firewall that does not permit incoming connections to its Gnutella port. If a direct connection cannot be established, the servent attempting the file download may request that the servent sharing the file push the file instead. A servent can request a file push by routing a Push request back to the servent that sent the QueryHit descriptor describing the target file.
The file download protocol is HTTP. The Gnutella protocol provides support for the HTTP Range parameter, so that interrupted downloads may be resumed at the point at which they terminated.
Gnutella uses a UUID (Unique Universal Identifier) and TTL (time to live) to control routing. A Gnutella packet includes these three fields in it�s head:
The UUID is used to avoid loops when a servent receives a packet that it has already sent. The TTL is started at some default value based on the expected size of the network, and the Hops value is effectively an inverse of the TTL during the travel of the packet. As a descriptor is passed from servent to servent, the TTL and Hops fields of the header must satisfy the following condition: TTL(0) = TTL(i) + Hops(i) Each servent will decrement the TTL before passing it on to another servent. passed to all known servents? When the TTL reaches 0, the descriptor will no longer be forwarded. The TTL is the only mechanism for expiring descriptors on the network. The actual downloads are done by point-to-point connections, meaning that the IP addresses of server and reader are both revealed to each other.
Gnutella traffic has passed the point where peers connected by modems are able to keep up. This has caused a change in the characteristics of network traffic [6]. Prior to this, each peer would be connected to about 1000 other peers. Afterwards, it dropped to a few hundred.
JXTA is a recently publicised P2P system. There are several points to note about JXTA
JXTA uses
In order to invoke services or make requests of one another, peers have first find each other. Peer discovery can be done in a variety of ways:
These peer discovery methods allow a dynamic set of peer relationships to be built up - at the expense of network traffic, particularly at startup of a new peer.
The lowest level of searching for services is by the Peer Discovery Protocol. Peers are distinguished by being "ordinary" peers or by being "rendezvous" peers. Ordinary peers keep information about the services they offer. Rendezvous peers cache service adverts so that they act as proxies for service adverts (just for the adverts, not the services themselves). Searching involves
Services are described using WSDL. The way a service is invoked is not prescribed except that they are invoked using JXTA pipes. The invocation mechanism through a pipe could be by SOAP, for example.
JXTA does not prescribe the scope of messages. A message sent from one peer could be received by all peers and forwarded to all the peers they know about. To avoid the resultant message flood, message transmission is limited in the current implementation to the peer groups the peer belongs to. In effect, this is bounding multicast scope to the peer group rather than to the local LAN.
Jini addresses issues in distributed computing by making the assumption that Java bytecodes can be interpreted everywhere, and so can build an infrastructure based on mobile Java objects. Web services are traditional client server systems with a possibly more business-object oriented name service than in most client-server systems. Napster and Gnutella are both designed for file sharing, which is more limited in scope, but extremely popular for certain types of files. JXTA is an experimental project to investigate some issues in peer-to-peer systems
It is possible to build bridges between many of these systems, so that JXTA peers can invoke Jini services, and similarly Jini clients can access Web services. Several projects are looking at such bridges.
Centralised network systems run the risk of hogging all the traffic, and hence requiring bigger pipes. Decentralised systems run the risk of generating excess traffic as peer nodes keep in touch with one another. This paper has discussed some of these issues for a number of current systems.