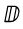
 . It is in the "Latin-1 Supplement" code chart
. It is in the "Latin-1 Supplement" code chart
00C5;LATIN CAPITAL LETTER A WITH RING ABOVE;Lu;0;L;0041 030A;
212B;ANGSTROM SIGN;Lu;0;L;00C5;
Angstrom sign is equivalent to U+00C5 which in turn is
equivalent to U+0041 U+030A
FB01;LATIN SMALL LIGATURE FI;Ll;0;L;<compat> 0066 0069;
| Not followed by canonical composition | Followed by canonical composition | |
|---|---|---|
| Canonical decomposition |
|
|
| Compatable decomposition |
|
|
start at next section
Character class has a number of static methods to
give character properties
getDirectionality(char ch)
Returns the Unicode directionality property for the given character.
getType(char ch)
Returns a value indicating a character's general category,
such as COMBINING_SPACING_MARK, CURRENCY_SYMBOL, DASH_PUNCTUATION,
DECIMAL_DIGIT_NUMBER, END_PUNCTUATION, ...
isDigit(char ch)
Determines if the specified character is a digit.
isLetter(char ch)
Determines if the specified character is a letter.
isLetterOrDigit(char ch)
Determines if the specified character is a letter or digit.
isLowerCase(char ch)
Determines if the specified character is a lowercase character.
isSpaceChar(char ch)
Determines if the specified character is a Unicode space character.
isTitleCase(char ch)
Determines if the specified character is a titlecase character.
isUpperCase(char ch)
Determines if the specified character is an uppercase character.
toLowerCase(char ch)
Converts the character argument to lowercase using case mapping information from the UnicodeData file.
toTitleCase(char ch)
Converts the character argument to titlecase using case mapping information from the UnicodeData file.
toUpperCase(char ch)
Converts the character argument to uppercase using case mapping information from the UnicodeData file.
java.lang.CharacterData is responsible
for storing and accessing Unicode character data
Character.isLetter() are passed
to CharacterData
00 00 FF FE UCS-4, big-endian
FF FE 00 00 UCS-4 little-endian
EF BB BF UTF-8
FE FF UCS-2 or UTF-16, big-endian
FF FE UCS-2 or UTF-16, little-endian