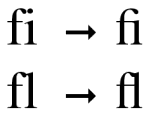
Oct Dec Hex Char Oct Dec Hex Char
------------------------------------------------------------
000 0 00 NUL '\0' 100 64 40 @
001 1 01 SOH 101 65 41 A
002 2 02 STX 102 66 42 B
003 3 03 ETX 103 67 43 C
004 4 04 EOT 104 68 44 D
005 5 05 ENQ 105 69 45 E
006 6 06 ACK 106 70 46 F
007 7 07 BEL '\a' 107 71 47 G
010 8 08 BS '\b' 110 72 48 H
011 9 09 HT '\t' 111 73 49 I
012 10 0A LF '\n' 112 74 4A J
013 11 0B VT '\v' 113 75 4B K
014 12 0C FF '\f' 114 76 4C L
015 13 0D CR '\r' 115 77 4D M
016 14 0E SO 116 78 4E N
017 15 0F SI 117 79 4F O
020 16 10 DLE 120 80 50 P
021 17 11 DC1 121 81 51 Q
022 18 12 DC2 122 82 52 R
023 19 13 DC3 123 83 53 S
024 20 14 DC4 124 84 54 T
025 21 15 NAK 125 85 55 U
026 22 16 SYN 126 86 56 V
027 23 17 ETB 127 87 57 W
030 24 18 CAN 130 88 58 X
031 25 19 EM 131 89 59 Y
032 26 1A SUB 132 90 5A Z
033 27 1B ESC 133 91 5B [
034 28 1C FS 134 92 5C \ '\\'
035 29 1D GS 135 93 5D ]
036 30 1E RS 136 94 5E ^
037 31 1F US 137 95 5F _
040 32 20 SPACE 140 96 60 `
041 33 21 ! 141 97 61 a
042 34 22 " 142 98 62 b
043 35 23 # 143 99 63 c
044 36 24 $ 144 100 64 d
045 37 25 % 145 101 65 e
046 38 26 & 146 102 66 f
047 39 27 ' 147 103 67 g
050 40 28 ( 150 104 68 h
051 41 29 ) 151 105 69 i
052 42 2A * 152 106 6A j
053 43 2B + 153 107 6B k
054 44 2C , 154 108 6C l
055 45 2D - 155 109 6D m
056 46 2E . 156 110 6E n
057 47 2F / 157 111 6F o
060 48 30 0 160 112 70 p
061 49 31 1 161 113 71 q
062 50 32 2 162 114 72 r
063 51 33 3 163 115 73 s
064 52 34 4 164 116 74 t
065 53 35 5 165 117 75 u
066 54 36 6 166 118 76 v
067 55 37 7 167 119 77 w
070 56 38 8 170 120 78 x
071 57 39 9 171 121 79 y
072 58 3A : 172 122 7A z
073 59 3B ; 173 123 7B {
074 60 3C < 174 124 7C |
075 61 3D = 175 125 7D }
076 62 3E > 176 126 7E ~
077 63 3F ? 177 127 7F DEL
Char Dec Oct Hex | Char Dec Oct Hex | Char Dec Oct Hex | Char Dec Oct Hex
-------------------------------------------------------------------------------------
(nul) 0 0000 0x00 | (sp) 32 0040 0x20 | @ 64 0100 0x40 | ` 96 0140 0x60
(soh) 1 0001 0x01 | ! 33 0041 0x21 | A 65 0101 0x41 | a 97 0141 0x61
(stx) 2 0002 0x02 | " 34 0042 0x22 | B 66 0102 0x42 | b 98 0142 0x62
(etx) 3 0003 0x03 | # 35 0043 0x23 | C 67 0103 0x43 | c 99 0143 0x63
(eot) 4 0004 0x04 | $ 36 0044 0x24 | D 68 0104 0x44 | d 100 0144 0x64
(enq) 5 0005 0x05 | % 37 0045 0x25 | E 69 0105 0x45 | e 101 0145 0x65
(ack) 6 0006 0x06 | & 38 0046 0x26 | F 70 0106 0x46 | f 102 0146 0x66
(bel) 7 0007 0x07 | ' 39 0047 0x27 | G 71 0107 0x47 | g 103 0147 0x67
(bs) 8 0010 0x08 | ( 40 0050 0x28 | H 72 0110 0x48 | h 104 0150 0x68
(ht) 9 0011 0x09 | ) 41 0051 0x29 | I 73 0111 0x49 | i 105 0151 0x69
(nl) 10 0012 0x0a | * 42 0052 0x2a | J 74 0112 0x4a | j 106 0152 0x6a
(vt) 11 0013 0x0b | + 43 0053 0x2b | K 75 0113 0x4b | k 107 0153 0x6b
(np) 12 0014 0x0c | , 44 0054 0x2c | L 76 0114 0x4c | l 108 0154 0x6c
(cr) 13 0015 0x0d | - 45 0055 0x2d | M 77 0115 0x4d | m 109 0155 0x6d
(so) 14 0016 0x0e | . 46 0056 0x2e | N 78 0116 0x4e | n 110 0156 0x6e
(si) 15 0017 0x0f | / 47 0057 0x2f | O 79 0117 0x4f | o 111 0157 0x6f
(dle) 16 0020 0x10 | 0 48 0060 0x30 | P 80 0120 0x50 | p 112 0160 0x70
(dc1) 17 0021 0x11 | 1 49 0061 0x31 | Q 81 0121 0x51 | q 113 0161 0x71
(dc2) 18 0022 0x12 | 2 50 0062 0x32 | R 82 0122 0x52 | r 114 0162 0x72
(dc3) 19 0023 0x13 | 3 51 0063 0x33 | S 83 0123 0x53 | s 115 0163 0x73
(dc4) 20 0024 0x14 | 4 52 0064 0x34 | T 84 0124 0x54 | t 116 0164 0x74
(nak) 21 0025 0x15 | 5 53 0065 0x35 | U 85 0125 0x55 | u 117 0165 0x75
(syn) 22 0026 0x16 | 6 54 0066 0x36 | V 86 0126 0x56 | v 118 0166 0x76
(etb) 23 0027 0x17 | 7 55 0067 0x37 | W 87 0127 0x57 | w 119 0167 0x77
(can) 24 0030 0x18 | 8 56 0070 0x38 | X 88 0130 0x58 | x 120 0170 0x78
(em) 25 0031 0x19 | 9 57 0071 0x39 | Y 89 0131 0x59 | y 121 0171 0x79
(sub) 26 0032 0x1a | : 58 0072 0x3a | Z 90 0132 0x5a | z 122 0172 0x7a
(esc) 27 0033 0x1b | ; 59 0073 0x3b | [ 91 0133 0x5b | { 123 0173 0x7b
(fs) 28 0034 0x1c | < 60 0074 0x3c | \ 92 0134 0x5c | | 124 0174 0x7c
(gs) 29 0035 0x1d | = 61 0075 0x3d | ] 93 0135 0x5d | } 125 0175 0x7d
(rs) 30 0036 0x1e | > 62 0076 0x3e | ^ 94 0136 0x5e | ~ 126 0176 0x7e
(us) 31 0037 0x1f | ? 63 0077 0x3f | _ 95 0137 0x5f | (del) 127 0177 0x7f
(ASCII table)
This ASCII set is US ASCII
| ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > |
| @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N |
| P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ |
| ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n |
| p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ |
#define MAX 32??=define MAX 32This is from A tutorial on character code issues by Jukka Korpela (this is really good!)
| dec | oct | hex | glyph | official Unicode name | National variants |
|---|---|---|---|---|---|
| 35 | 43 | 23 | # | number sign | £ Ù |
| 36 | 44 | 24 | $ | dollar sign | ¤ |
| 64 | 100 | 40 | @ | commercial at | É § Ä à ³ |
| 91 | 133 | 5B | [ | left square bracket | Ä Æ ° â ¡ ÿ é |
| 92 | 134 | 5C | \ | reverse solidus | Ö Ø ç Ñ ½ ¥ |
| 93 | 135 | 5D | ] | right square bracket | Å Ü § ê é ¿ | |
| 94 | 136 | 5E | ^ | circumflex accent | Ü î |
| 95 | 137 | 5F | _ | low line | è |
| 96 | 140 | 60 | ` | grave accent | é ä µ ô ù |
| 123 | 173 | 7B | { | left curly bracket | ä æ é à ° ¨ |
| 124 | 174 | 7C | | | vertical line | ö ø ù ò ñ f |
| 125 | 175 | 7D | } | right curly bracket | å ü è ç ¼ |
| 126 | 176 | 7E | ~ | tilde | ü ¯ ß ¨ û ì ´ _ |

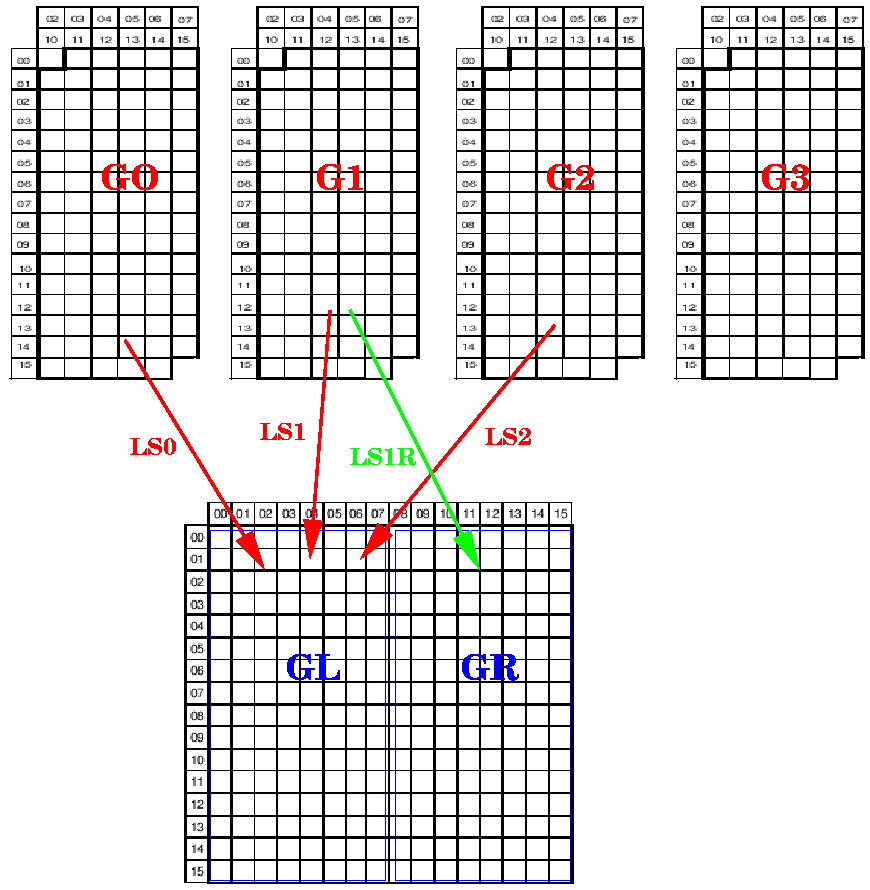
LS1 N/M prints 'a'
LS1R (N+8)/M also prints 'a'
There is a discussion of Japanese character sets at http://www.debian.org/doc/manuals/intro-i18n/ch-languages.en.html
System.out which is of type
PrintStream
xtern -fn '-urw-urw palladio l-medium-r-normal--0-0-0-0-p-0-iso8859-2'
System.out.write(65); // 'A'
System.out.write(0xA1); // in ISO 8859-2, an 'A' with a cedilla?
java.nio.charset.Charset
is "a named mapping between sequences of sixteen-bit Unicode
characters and sequences of bytes"
InputStreamReader and
OutputStreamWriter have constructors which take
a Charset parameter, and perform conversion
as they read and write
LATIN SMALL LIGATURE FFI, and similar
"Arabic Presentation Forms"
Label
requires support from the underlying window system since
they use "native" window objects (the Java Label
uses a "peer" object - a Motif XmLabel under
X Windows)
Font f = new Font("Serif", Font.PLAIN, 12)JRE_HOME/lib/fonts. e.g in Fedora Linux RC2:
font.properties
font.properties.ja
font.properties.ja.Redhat6.1
font.properties.ja.Redhat6.2
font.properties.ja.Redhat7.2
font.properties.ja.Redhat7.3
font.properties.ja.Redhat8.0
font.properties.ja.Turbo
font.properties.ja.Turbo6.0
font.properties.ko.Redhat8.0
font.properties.Redhat6.1
font.properties.Redhat8.0
font.properties.SuSE8.0
font.properties.zh_CN.Redhat8.0
font.properties.zh.Turbo
font.properties.zh_TW.Redhat8.0
serif.0=-b&h-lucidabright-medium-r-normal--*-%d-*-*-p-*-iso8859-1
serif.italic.0=-b&h-lucidabright-medium-i-normal--*-%d-*-*-p-*-iso8859-1
serif.bold.0=-b&h-lucidabright-demibold-r-normal--*-%d-*-*-p-*-iso8859-1
(to the right of the '=' is a pattern for an X Windows font name).
These are all ISO 8859-1 fonts
/usr/X11R6/lib/X11/fonts/.
e.g in the subdirectory 75dpi the file fonts.dir
has lines like
lubI10-ISO8859-1.pcf.gz -b&h-lucidabright-medium-i-normal--10-100-75-75-p-57-iso8859-1
which map the X Windows font name to an actual font file lubI10-ISO8859-1.pcf.gz
xfd
xfd -fn '-b&h-lucidabright-medium-r-normal--*-*-*-*-p-*-iso8859-1
JRE_HOME/lib/fonts
fonts.dir lists the font files included in each TrueType
file e.g. the entry for LucidaTypewriterRegular.ttf contains
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-ascii-0
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-fcd8859-15
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso10646-1
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-1
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-10
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-15
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-2
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-3
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-4
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-5
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-6
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-7
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-8
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-iso8859-9
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-koi8-r
-b&h-Lucida Sans Typewriter-medium-r-normal--0-0-0-0-m-0-koi8-ru
This file contains various 8-bit fonts


This program lists the fonts families known to Java These can be used to create fonts as in
Font f = new Font("Bitstream Charter", Font.PLAIN, 12);
java.awt.Font[family=Bitstream Charter,name=Bitstream Charter Bold,style=plain,size=1]
ttfonts-zh will have the zysong.ttf
TrueType fonts. The Cyberbit.ttf font is available
from e.g.
http://www.carfield.com.hk/mirror/pub/font/Cyberbit.ttf
JRE_HOME/lib/fonts.
For X Windows, run ttmkfdir > fonts.dir
to regenerate the font directory
Font font = new Font("ZYSong18030", Font.PLAIN, 24); // or
font = new Font("Bitstream Cyberbit", ...)
font.properties files in JRE_HOME/lib
Cyberbit.ttf is 13 Megabytes
Font has methods
canDisplay() and canDisplayUpTo()
to check if the font will display characters and strings
This is based on a program from Chinese in Java