The Web is made up predominantly of two technologies:
Whenever you visit a Web site, it will consist of lots of text laid out in some way. These are HTML pages. The pages may also contain images. Some of the text (and some of the images) will be "clickable", that will take you to another Web page when you click the mouse on them. Sometimes you will get a Word document, a PowerPoint slide, a movie file, an audio file, etc, but most times you will get another HTML page.
HTML is called a "markup language". The text is interspersed with "tags" which give instructions to the browser about how to layout the text in the screen. The original HTML language was very simple, with tags to describe various levels of headers, lists and text emphasis. It has become progressively more complex, so that nowadays only a few retrogrades like me will edit HTML directly.
In this chapter we describe enough of HTML and associated technologies so that you can fit this into the picture of metadata.
Before looking at the structure of an HTML document, let's look at who is going to reading these documents. People will use a browser to read a Web page, such as Firefox, Chrome or Internet Explorer. However, it isn't only browsers that will read HTML documents. Primary examples are search engines: while a user will read HTML pages produced by a search engine such as Google, Google must first have scoured the Web, reading pages and storing the information from them. There are a variety of such "crawlers" and "spiders", all roaming the web and reading HTML documents.
Collectively, browsers and these crawlers, spiders and others are known as "user agents". We will often use this generic term, as "browser" implies a human agent as the final consumer of the documents.
An HTML document consists of two parts
<HEAD> ... </HEAD>
<BODY> ... </BODY>
The header part contains a mixture of content, and usually the only bit of this that you see is the TITLE, which appears in the browser title bar. The rest consists of instructions to the browser and ... metadata. We shall see how this metadata is included when we look at the Dublin Core.
The body part consists of the text of the document, markups to show how to display it, and hyperlinks. The HTML for a typical "hello world" body might look like
<h1> Hello World </h1>
<p>
This page says
<ul>
<li> Hello World </li>
<li> Goodbye World </li>
</ul>
</p>
which would appear as
Hello World
This page says
- Hello World
- Goodbye World
The HTML markup language is very simple, even now after 20 years of development. There are many other markup languages in use, such as XML and LaTeX. They all have different aims and uses. HTML markup was designed just for simple text layout, and there is no semantics implied apart from this layout. For example, the paragraph tag <p> signifies a break in the text. It does not signify, say, that a new idea in the document is commencing. No such semantic meaning can be attached to it.
In my opinion, the Word Wide Web exploded for simple reasons
Linked documents were not new. What was new was the ease with which links could be made. No permissions needed to be sought; no complex "I link to you, you link to me" arrangements need to be made; no categorisation of links into types need be made, and so on. As a document author, if you liked the look or content of someone else's page, then you just made a link to it from yours. The format is simple
<a href="where your page is"> my description of your page </a>
as in
<a href="http://jan.newmarch.name/index.html"> Jan's home page </a>
In the earliest days of the Web, we all knew who was creating web sites and we manually linked our pages together. Then Yahoo tried to classify the Web, building big graphs - again manually - of concepts and sites with such content. But the Web kept growing, and when Google came along it introduced a whole new way of finding our way around this enormous set of linked pages.
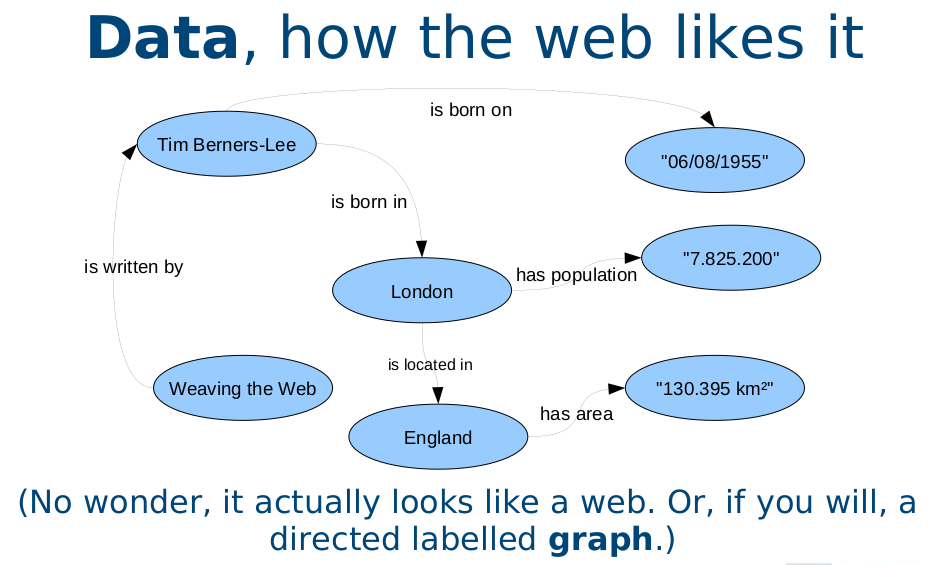
I recently came across the following slide from a talk on An Introduction to Linked Open Data :
Any claim that this is "how the web likes it" is simply false. All of the links in this figure are labelled "is born on", "is written by", etc. Hyperlinks on the web, on the other hand are not labelled in any such way: they are simply pointers from one place to another. To read anything more into an HTML hypertext link is just wishful thinking. To require such a labelling would require the re-writing of almost every Web page, would severely limit the ease of creating new pages, and, well, it's just not going to happen.
But would you like the web to be linked as in the previous diagram? That is one of the promises of the Semantic Web: that links are labelled and what's more, that the links have a semantic meaning which will allow rigorous and meaningful searches to be made, turning up those - and only those - documents that are relevant to a search.
As noted above, this won't be done by changing the Web. It can only be done by setting in place a parallel structure whereby content is explicitly created with appropriate metadata, or is retro-fitted with such data. The Dublin Core could have been a mechanism whereby this could happen within the Web, but that has had limited success so far. For example, the home page for the conference swib14 - Semantic Web in Libraries doesn't even have any Dublin Core metadata!
If you look at the Web pages for any business, government or education group, they will have menus, complex layouts, scrolling windows and so on. This kind of complexity cannot be achieved just by HTML. Instead, there are two extra features used in modern Web sites to achieve this. Note that these have absolutely no effect on any metadata content of the Web pages - they just increase the complexity of display. The two features are
Using these features directly is complex. Many Web designers use toolkits such as Drupal or JQuery which build complex Web pages using these tools. But as mentioned before, they are not related to any metadata.
This chapter has given a minimal coverage of some HTML concepts. To recap: