Introduction
This lecture looks at process management from the O/S point of view.
It covers process state, process creation and process scheduling.
There is also an introduction to inter-process communication (IPC).
Reference: Tanenbaum Chapter 2
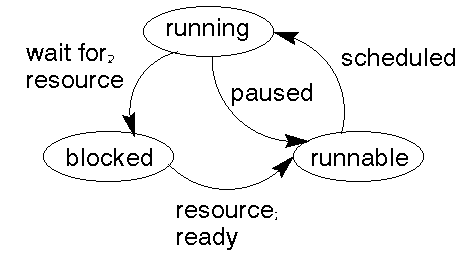
Process states
When a process is using the CPU, it is actually running and doing some work.
However, it will not always stay in that state.
If a process does I/O and the device is not ready or just slow, the process
will become blocked and be unable to do any more work until the I/O is complete.
In a multitasking environment, a process is not allowed to use the CPU all
the time. At intervals (maybe signalled by a timer interrupt) it will be stopped
by the O/S so that another process can run. In this state it is not running,
but is runnable.
The process states and transitions are
Process table
The O/S maintains information about each process in a process table. Entries
in this table are often called process control blocks and must contain information
about
- process state
- memory state
- resource state
for each process.
Process state
The process state must contain all the information needed so that the process
can be loaded into memory and run. This includes
- the value of each register
- the program counter
- the stack pointer
Information about the state that the process is in (runnning, runnable, blocked)
and why will need to be stored.
In addition it may contain extra fields such as:
- process ID of itself, its parent, etc.
- elapsed time.
- pending signals that have not yet been dealt with (eg they arrived while
the process was asleep).
Memory state
Pointers to the various memory areas used by the program need to be kept, so
that they can be relocated back as needed.
Resource state
The process will generally have files open, be in particular directory, have
a certain user ID, etc. The information about these will need to be stored
also.
For example, in Unix each process has a file table. The first entry in this
(file descriptor zero) is for the processes' standard input, the second entry
is for standard output, the third for standard error. Additional entries are
made when the process opens more files.
Linux process state
In Linux, the information stored per process is defined by the structure
struct task_struct {
/* these are hardcoded - don't touch */
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
long counter;
long priority;
unsigned long signal;
unsigned long blocked; /* bitmap of masked signals */
unsigned long flags; /* per process flags, defined below */
int errno;
int debugreg[8]; /* Hardware debugging registers */
struct exec_domain *exec_domain;
/* various fields */
struct linux_binfmt *binfmt;
struct task_struct *next_task, *prev_task;
struct sigaction sigaction[32];
unsigned long saved_kernel_stack;
unsigned long kernel_stack_page;
int exit_code, exit_signal;
unsigned long personality;
int dumpable:1;
int did_exec:1;
int pid,pgrp,session,leader;
int groups[NGROUPS];
/*
* pointers to (original) parent process, youngest child, younger siblin
g,
* older sibling, respectively. (p->father can be replaced with
* p->p_pptr->pid)
*/
struct task_struct *p_opptr, *p_pptr, *p_cptr, *p_ysptr, *p_osptr;
struct wait_queue *wait_chldexit; /* for wait4() */
unsigned short uid,euid,suid,fsuid;
unsigned short gid,egid,sgid,fsgid;
unsigned long timeout;
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
long utime, stime, cutime, cstime, start_time;
struct rlimit rlim[RLIM_NLIMITS];
unsigned short used_math;
char comm[16];
/* virtual 86 mode stuff */
struct vm86_struct * vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags, v86mask, v86mode;
/* file system info */
int link_count;
struct tty_struct *tty; /* NULL if no tty */
/* shm stuff */
struct shm_desc *shm;
struct sem_undo *semun;
/* ldt for this task - used by Wine. If NULL, default_ldt is used */
struct desc_struct *ldt;
/* tss for this task */
struct tss_struct tss;
/* filesystem information */
struct fs_struct fs[1];
/* open file information */
struct files_struct files[1];
/* memory management info */
struct mm_struct mm[1];
};
Process creation
When a process starts, the O/S has to build an entry for it in the process
table. The process state will be marked as ``runnable''.
Here is the Linux fork() routine:
/*
* Ok, this is the main fork-routine. It copies the system process
* information (task[nr]) and sets up the necessary registers. It
* also copies the data segment in its entirety.
*/
int do_fork(unsigned long clone_flags, unsigned long usp, struct pt_regs *regs)
{
int nr;
unsigned long new_stack;
struct task_struct *p;
if(!(p = (struct task_struct*)__get_free_page(GFP_KERNEL)))
goto bad_fork;
new_stack = get_free_page(GFP_KERNEL);
if (!new_stack)
goto bad_fork_free;
nr = find_empty_process();
if (nr < 0)
goto bad_fork_free;
*p = *current;
if (p->exec_domain && p->exec_domain->use_count)
(*p->exec_domain->use_count)++;
if (p->binfmt && p->binfmt->use_count)
(*p->binfmt->use_count)++;
p->did_exec = 0;
p->kernel_stack_page = new_stack;
*(unsigned long *) p->kernel_stack_page = STACK_MAGIC;
p->state = TASK_UNINTERRUPTIBLE;
p->flags &= ~(PF_PTRACED|PF_TRACESYS);
p->pid = last_pid;
p->p_pptr = p->p_opptr = current;
p->p_cptr = NULL;
p->signal = 0;
p->it_real_value = p->it_virt_value = p->it_prof_value = 0;
p->it_real_incr = p->it_virt_incr = p->it_prof_incr = 0;
p->leader = 0; /* process leadership doesn't inherit */
p->tty_old_pgrp = 0;
p->utime = p->stime = 0;
p->cutime = p->cstime = 0;
p->start_time = jiffies;
p->mm->swappable = 0; /* don't try to swap it out before it's set up *
/
task[nr] = p;
SET_LINKS(p);
nr_tasks++;
/* copy all the process information */
copy_thread(nr, clone_flags, usp, p, regs);
if (copy_mm(clone_flags, p))
goto bad_fork_cleanup;
p->semundo = NULL;
copy_files(clone_flags, p);
copy_fs(clone_flags, p);
/* ok, now we should be set up.. */
p->mm->swappable = 1;
p->exit_signal = clone_flags & CSIGNAL;
p->counter = current->counter >> 1;
p->state = TASK_RUNNING; /* do this last, just in case */
return p->pid;
bad_fork_cleanup:
task[nr] = NULL;
REMOVE_LINKS(p);
nr_tasks--;
bad_fork_free:
free_page(new_stack);
free_page((long) p);
bad_fork:
return -EAGAIN;
}
Process scheduling
The process scheduler is responsible for changing the state of processes.
A scheduler must compromise between certain desirable things:
- make sure each process gets a fair share of the CPU
- keep the CPU busy 100% of the time
- minimize response delays
- be consistent so that behaviour is expected
Stopping processes
There are two ways in which processes can stop: voluntarily stop, or be forced
to stop. If there is a mechanism to stop processes, then the scheduling is
preemptive, otherwise it is non-preemptive
or co-operative.
OS2 and Windows use non-preemptive schedulers. Windows NT and Unix use preemptive
schedulers.
To keep the CPU busy as much as possible, whenever a process blocks, it should
be replaced.
To only allow a process to run for a maximum amount of time, timer interrupts
can be set to stop the process.
When a process stops or is stopped, the registers have to be copied into the
process control block. Any values in the PCB that have changed will need to
be set. (Because of the register copy, the O/S code to do that would have to
be in Assembler.)
Round robin scheduling
This is one of the simplest scheduling algorithms. The O/S maintains a queue
of runnable processes. When a running process is stopped, or a blocked process
becomes runnable, it is placed on the end of the queue.
When the CPU becomes free, the process at the head of the queue is loaded and
made the running process.
Each process is allowed to run for a fixed maximum time before it is stopped.
This fixed time must be carefully tuned. If it is too long, then response time
for processes currently not running is too slow. If the time is too short,
then the system will spend proportionally more time swapping processes and
will just appear to be running slowly.
Priority scheduling
In round robin, all processes have the same priority. In priority scheduling
they may have different ones. The O/S will maintain lists of processes, one
for each priority. A runnable process from the highest priority list will be
chosen.
Priorities may be static (set at creation time) or dynamic. In Unix, the longer
a process runs, the lower its priority becomes.
Within a queue, a process may be chosen say by round robin.
Shortest job first
This is often used on batch systems. In these it is quite common to know in
advance about how long a job will take. Then the list of jobs can be ordered
on time required. The one needing the shortest time can be scheduled first.
This gives the best average time.
This cannot easily be used in interactive systems because you don't know how
long a command will take.
Two level scheduling
The above schemes assume either that all processes are in memory, or that only
one process (the currently running one) is in memory. Then the cost of context
switching is about equal.
The cost of context switching to a process that is in memory is that the registers
have to be loaded, and a jump made to the program counter.
The extra cost of context switching to a process that is not in memory is that
it first has to be loaded from disk. This will be significantly slower.
A two-level scheduler will maintain two lists, one for processes in main memory,
the other for those on disk. One scheduler will work on those in memory, switching
between them.
Periodically another scheduler will move processes between the lists so that
those on disk can have a chance to run.
Linux Scheduling
Here is part of the Linux scheduling function (the wakeup stuff belonging
to alalrm calls is omitted)
asmlinkage void schedule(void)
{
int c;
struct task_struct * p;
struct task_struct * next;
unsigned long ticks;
/* check alarm, wake up any interruptible tasks that have got a signal */
/* code omitted here - Jan */
/* this is the scheduler proper: */
c = -1000;
next = p = &init_task;
for (;;) {
if ((p = p->next_task) == &init_task)
goto confuse_gcc2;
if (p->state == TASK_RUNNING) {
nr_running++;
if (p->counter > c)
c = p->counter, next = p;
}
}
confuse_gcc2:
if (!c) {
for_each_task(p)
p->counter = (p->counter >> 1) + p->priority;
}
if (current == next)
return;
kstat.context_swtch++;
switch_to(next);
}
The full scheduling code is available as
sched.c
and
sched.h
where switch_to is implemented as a macro for speed:
/*
* switch_to(n) should switch tasks to task nr n, first
* checking that n isn't the current task, in which case it does nothing.
* This also clears the TS-flag if the task we switched to has used
* tha math co-processor latest.
*/
#define switch_to(tsk) \
__asm__("cli\n\t" \
"xchgl %%ecx,_current\n\t" \
"ljmp %0\n\t" \
"sti\n\t" \
"cmpl %%ecx,_last_task_used_math\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
: /* no output */ \
:"m" (*(((char *)&tsk->tss.tr)-4)), \
"c" (tsk) \
:"cx")
Windows 95 Scheduling
When Windows95 runs an MSDOS application it does so using a ``virtual 8086''.
This is a process that has its own 1M address space. The process does not
have access to any other resources. So an MSDOS application cannot crash
the system any more.
Since MSDOS is not multitasking, the only way it can
create new processes is as sequential ones. Scheduling is not an issue
here, since each process has to run to completion before a parent can
resume. Such multiple processes created within MSDOS are not visible
to Windows95.
All Windows 3.1 applications run within a shared address space. It is not
possible to change the scheduling algorithm without breaking many Windows
3.1 applications, so the cooperative scheduling mechanism must remain
for these.
It is possible for one Windows 3.1 application to lock out others, just
as it happens under Windows 3.1. There is no change in this. However,
whena Windows 3.1 application crashes, it can only bring down the other
Windows 3.1 applications that are running.
Windows 32-bit applications each run within their own protected memory
space. No Windows 32-bit application can crash another by corrupting its
memory because it does not have access (unless deliberately shared).
Each 32-bit application may use threads internally, so that a
32-bit application may be one process with multiple threads.
An MSDOS application is one process and one thread.
Each Windows 3.1 application is one process and one thread.
The Windows 95 scheduler manages threads rather than processes.
The scheduler is pre-emptive so that one process cannot lock out others
(see caveats later). The scheduler uses priority scheduling where a thread
can have a priority between 0 and 31. If multiple processes have the same
priority, round robin is used.
The time slice defaults to 20ms, but the scheduler has the ability to change
this. It can also temporarily bump up priorities if needed (e.g. in
response to a mouse click). I don't know the full details of the algorithm.
The caveat is as follows: Windows 3.1 16-bit system code is not ``re-entrant''.
That is, it is not possible to interrupt a Windows 3.1 system call and
restart it, later continuing with the interrupted call. This is why
Windows 3.1 scheduling must be cooperative rather than preemptive
because the system calls cannot be interrupted.
To ensure that two processes do not attempt to run Windows 3.1 system
calls simultaneously, Windows 95 uses a ``semaphore'' (see next
lecture) to control access.
Some Windows 95 32-bit code calls the old Windows 3.1 16-bit code. Not
much, but some. So if a Windows 3.1 application won't terminate and
release the semaphore, then the 32-bit code can't call the 16-bit code.
So a 32-bit application will block at that point.
If all 32-bit applications hit 16-bit code, then they will all block
and the system will. Killing the offending 16-bit application will
allow the rest to proceed.
Unix process startup
When a system boots Unix, it creates a single process called ``init''. This
init acts as the root of the process tree.
init forks a set of copies of itself, one for each terminal line that is connected
to it. Each one of these type the login message and then blocks waiting for
terminal input.
When the user name and password are typed, init checks that the user is valid,
and if so changes to the user's home directory, resets the user ID of the process
to the user, and ``exec''s a shell.
At this point the init for that terminal line has been replaced by the login
shell for that user. The user does whatever they want to do, and eventually
logs out.
Logging out terminates the login shell. In the meantime, the init at the top
of the process tree has done a wait, waiting on any of its children. The login
shell is in fact a direct child of this toplevel init because it came from
exec-ing a child. So when the shell terminates, the toplevel init wakes up.
The toplevel init then forks a new init for that terminal line and starts a
wait again, for another child to terminate.
Intro to InterProcess Communication
Processes do not run in isolation from each other. Generally they need to communicate
with each other.
Example:
Any two processes in a pipeline are communicating. One sends a stream of bytes
to the other.
Example:
Access to the lineprinter is controlled by a single process called ``lpd''
(the lineprinter daemon). Each time a user runs ``lpr'' this has to communicate
with ``lpd'' and send it the file to print.
Example:
Your home directories are stored on the machine ``willow''. Each time you access
a file the O/S has to make a connection to willow, request the file from a
suitable process on willow and accept responses from it.
There are many models of IPC, with different advantages and problems.
Shared memory
If two processes share the same piece of memory then they can use this to communicate.
For example, one may write information in this shared area and the other may
read it.
This can be a very fast method of information transfer because RAM can be used.
Synchronisation is a major problem - if the first process keeps writing data,
how can it ensure that the second one reads it?
Pipeline
A pipe acts like a channel betwen two processes. When one process writes into
the pipe the other process can read from it. A pipe can usually buffer information
so that the writer can place a lot of information in the pipe before the child
has to read it. When the pipe becomes full the writer has to suspend.
Pipes can be un-named. This is the norm in Unix where a process creates a pipe
and then forks, so that the two processes share the pipe between them.
If the processes do not come from a common ancestor then they can only share
a pipe if they can both name it (otherwise they could not find it). Named pipes
usually appear as though they were files in the file system.
Streams
Pipes carry unstructured data - you put bytes in one end and get the same bytes
out the other. Streams are designed to carry record information - you put records
in at one end and get the same records out the other. Each record must contain
a field saying how large it is.
Sockets
Sockets are more like ports that you can send data to. A process will be ``listening''
at a port and will accept data sent to it.
Signals
Signals are a fairly crude method if IPC. A process may send a signal to another
such as ``wake up'' or ``die''. The other process can respond to these signals
in various ways.
This page is
http://pandonia.canberra.edu.au/OS/l8_2.html,
copyright Jan Newmarch.
It is maintained by Jan Newmarch.
email:
jan@ise.canberra.edu.au
Web:
http://pandonia.canberra.edu.au/
Last modified: 29 August, 1995