Tanenbaum Chapter 3
Swapping
Even allowing multiple processes to reside in memory simultaneously is not
sufficient to allow good multitasking.
If a process has a probability of p of being idle while waiting for I/O, then
for N processes the probability that all are idle is p^N - which will never
be zero.
This time is wasted, especially if other processes would be able to execute
if there was room in memory for them to run.
A solution is ``swapping''. When a process is idle, the program itself and
all data areas that it is using can be copied out to disk, freeing the main
memory for use by other processes.
Choosing which processes to swap, etc belong to ``process management''. What
we need now is to see the effect on memory management.
In order to swap processes to disk, there must be a swap area on the disk.
This is usually of fixed size, and larger than RAM, so that it can hold many
more non-running processes than fit into RAM.
For example, my Sun has 24M RAM, 64M swap. My Linux PC at home has 4M RAM,
16M swap.
This swap area will have free space as well as used space, and so must be
managed just like RAM. It will have free and used lists, and some memory
allocation scheme will be needed.
When a running process requests more RAM, it can be given it if there is some
available, or non-running processes can be swapped out to disk to create this
extra space. If there is no space on the disk, the memory request will probably
fail. In this case, the user often has to reduce the number of processes using
RAM and swap space before enough processes can be swapped out to allow this
program to get enough RAM.
Windows uses swapping. In most uses it creates a temporary dynamically-sized
swap file on startup and deletes it on exit (\windows\win386.swp). It can also
use fixed size swap files or use a disk partition.
Overlays
Sometimes the entire program may be too large to ever fit into RAM. The simplest
scheme relies on the programmer breaking it into logically smaller pieces known as overlays.
A main part runs all the time. Overlay instructions cause the O/S to replace
part of a program with another. The permanently running part calls procedures
in the overlays, which return back to it after completion.
This requires the programmer to structure their program into separate modules,
communicating only through the resident program. Once structured, the O/S can
do the rest.
This method was once commonly used in MSDOS.
Segments
A finer grained scheme than this allows partitioning not only of program code,
but of all elements into segments. Individual segments can then be swapped
out to disk as the need arises.
The 80x86 series offer hardware support for segments. Segments have a maximum
size of 64k. An address is composed of two parts: a 16-bit segment address
and a 16-bit offset address.
To find the actual address, the segment is shifted left by four bits and then
the offset is added. The actual address is then a 20-bit address with a 1M
address space.
Relocation is easy for addressing within a segment with this scheme, as the
segment address just needs to be reset.
This leads to different ``memory models'' for the PC:
- tiny model. Program and data in one 64k segment.
- small model. Program in one, data in another.
- medium model. Program in many, data in one.
- compact model. Program in one, data in many.
- large model. Program in many, data in many.
The disadvantage with this scheme is that it makes it hard to have data or
program structures larger than a segment size. For example, a 65k array in
MSDOS requires the ``huge'' memory model which is slow as all addresses have
to be ``normalised'' to remove ambiguity in addressing.
Virtual addressing
The segmentation model is still visible to many parts of the system. It can
be hidden further by by making ordinary programs use virtual addresses. These
then have to be mapped onto physical addresses by the hardware.
The program then just uses these virtual addresses, and the hardware and the
O/S between them worry about the physical addresses.
This makes it easy as far as an application is concerned, because it does not
have to worry about how much physical memory is available, about swapping or
about relocation problems.
Paging
The memory is divided into fixed sized regions called page frames. Programs
and data are divided into fixed sized portions called pages. The size of a
page frame is the same as the size of a page.
When loading a program any page of the program can be placed in any unused
page frame. This requires a page table to keep track of the mapping between
pages and page frames.

This shows that page 0 (logical/virtual) maps into page frame 3 (physical),
page 2 (logical) maps into page frame 0 (physical). Page 1 (logical) has no
mapping into a physical address.
If the page size is 1k, this can also be written
- LA 0k-1k -> PA 3k-4k
- LA 1k-2k -> ?
- LA 2k-3k -> PA 0k-1k
- LA 3k-4k -> PA 1k-2k
A logical address of say 2051 (=2048+3) maps into physical address 0k+3 = 3.
There is one page table per process - the pages belong to each individual process.
The page frames are the real memory.
This mapping must be performed by hardware, and must be fast because it affects every memory reference.
The way this is done depends on the hardware. For example, there may be a page
table register holding the base of the table as a table in RAM, and this gets
set for each process.
The hardware has to translate addresses. The other thing it has to do is to
generate a page fault interrupt when there is no entry for the logical address.
The O/S has to trap that interrupt and take appropriate action. The actions
are twofold: remove a page from memory if neccessary, and load the missing
page into memory.
Page removal
The O/S will load a missing page if needed. However, there may not be any space
for it because all page frames have something in them. In this case a page
must be removed first.
Which is the best frame to remove? The one that will not ever be used again,
or failing that the one that will not be used for the longest time. Requires
clairvoyance.
Least recently used
This attempts to predict future use by looking at past use. If a page has been
recently used then it is likely that it will be needed again soon.
This is because of sequential code and loops, which tend to re-execute the
same or close bits of program code.
So remove something that has not been used for the longest time, hoping that
it will not be needed soon.
This requires that a list be kept of usage of each page, in order of last use.
Whenever a memory reference occurs, this list must be updated, moving pages
around to keep the list up to date.
This makes this system prohibitively expensive in general.
Not recently used
This divides pages into two classes: those that have been used recently and
those that haven't. A single bit in the page table can be used for this. Whenever
a page is accessed, this bit is set.
If a page should be removed, one with the bit unset is a good candidate.
To ensure that there are pages with bits unset, on a periodic basis all pages
have their used bit set to zero.
FIFO (first in first out)
This is also simple to implement. Rather than predicting on recent usage, it
predicts on time of loading. The oldest in memory are the first to go. This
is just a queue,and can be maintained by pointers in the page table.
Removal to where?
If a page has not ever been changed, it can be discarded. If it is needed again
it can be reloaded from the original disk file. If it has been changed then
it must be kept in the swap area.
Supervisor mode
All of these memory manipulation algorithms must be run in supervisor mode
to gain access to the memory where the tables are kept and to manipulate all
processes.
Page loading
If a page is not in memory and is requested, it may be in the swap area. If
so, it should be loaded from there. Should it be in the swap area?
In demand paging pages are only loaded from the original files when needed.
So the answer is: not if demand page loading is used. Otherwise, all pages
possibly required would have to be loaded into either memory or swap when the
program is first started.
Shared pages
This is another technique for squeezing more out of the available memory. In
a timesharing system it is common for multiple versions of a program to be
running (eg many shells). If they can share pages then this cuts memory usage.
Pages can be shared if they have readable data only - if the data can be changed
then separate copies are needed. A compiler may divide the data areas into
read-only that can be shared, and writeable that cannot.
This technique is also extended to dynamic linking of libraries. Libraries
are strong candidates for shared pages across different programs. They are
also in every compiled program.
Both to save disk space and to allow easier indentification of sharing, these
are often not linked in until load time.
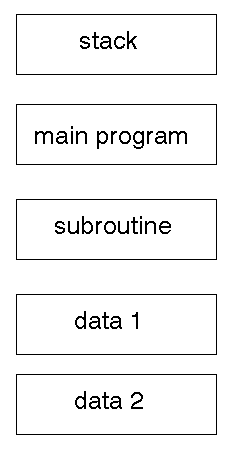
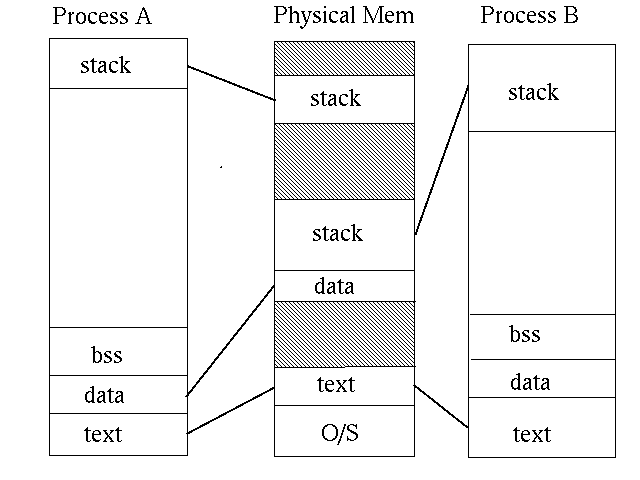
Unix Memory
The memory for any process is divided into
-
text - relocatable program code (fixed size)
-
data - fixed data such as static variables, strings (fixed size)
-
stack - user stack (grows downwards)
-
bss - unitialised data for the heap (grows upwards)
In a virtual memory system (which all modern Unix's are) this may look like
Windows NT Memory
Windows NT is a 32-bit O/S which can also run Windows 3.1 and MSDOS
applications. It is a multi-threaded system with pre-emptive multitasking
for the 32-bit NT applications.
It uses a virtual memory system of 4Gbytes
for each process. Of this, 2Gb is reserved for use by the O/S,
and the remaining 2Gb for the process (and its threads). The process cannot
access the O/S space except by switching to a different protection ring.
The O/S kernel is based on the micro-kernel Mach system (see later).
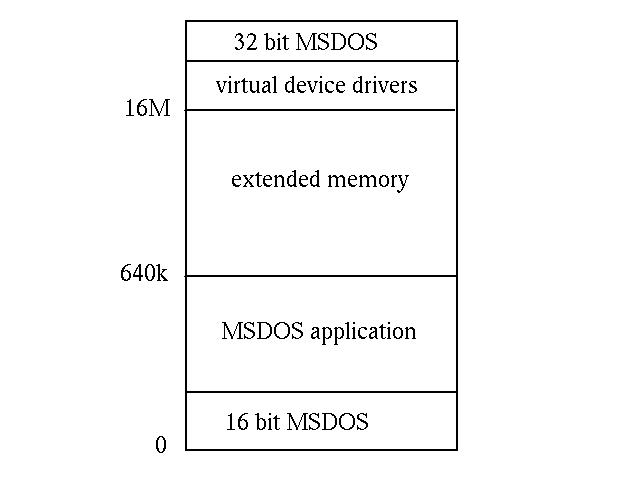
Each MSDOS application runs as a single thread in a 16M virtual address space.
This is organised so that MSDOS occupies the lowest portion, sharing the
bottom 640k with an MSDOS application. The device drivers are above the 16M
boundary. Each MSDOS application looks like
The entire set of Windows 3.1 applications all run within one of these
MSDOS virtual spaces. Each runs as a separate Windows NT thread.
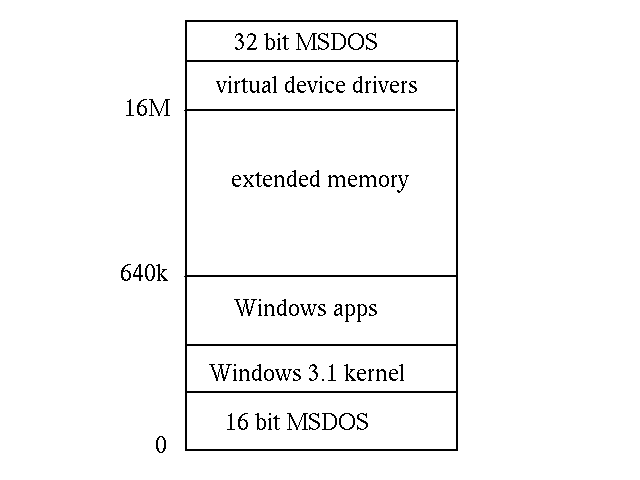
A set of applications will look like
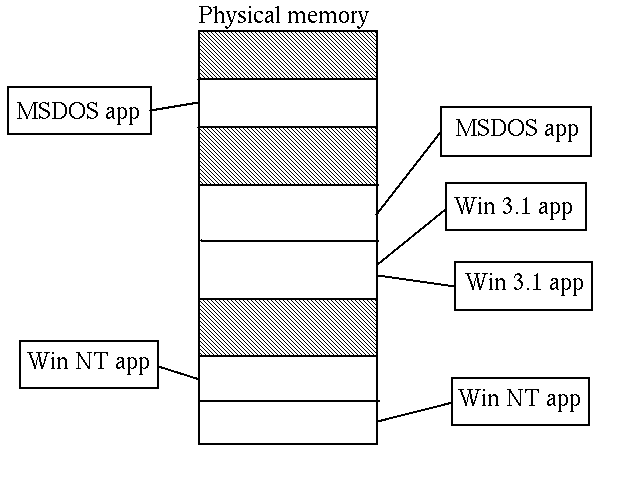
The process scheduler for Windows NT is pre-emptive, so no thread can hog
the system. The scheduler is a priority scheduler. However, Windows 3.1
threads are scheduled cooperatively amongst themselves.
Windows 95 Memory
The Windows 95 memory model is quite similar to Windows NT. Each MSDOS
application executes as a thread within its own address space. All Windows
3.1 applications share the same address space. Each 32-bit application
has its own address space. Each thread has 2G for its own use, and 2G used
by the O/S
The primary difference between the memory models is the protection given
to the system space within each processes address space. In Windows NT this
can only be accessed by switching to supervisor mode. In Windows 95 this can
be accessed by a simple function call without a switch. This is for speed.
The space is actually occupied by system device drivers, Windows DLLs,
and shared objects including nonsystem DLLs. So a Windows 95 application
can still trash quite a lot of important stuff.
Layered model
The layered model is the current model for many Operating Systems, including most flavours of Unix, VMS, etc. It gives a structure such as
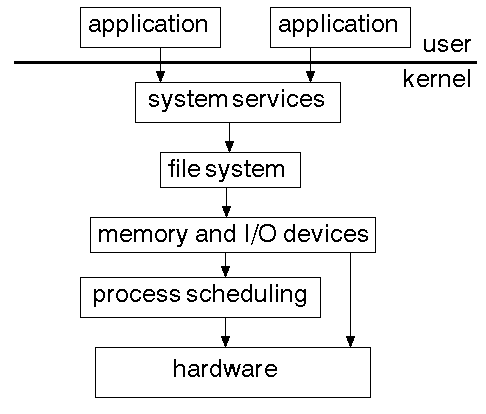
Client Server Model
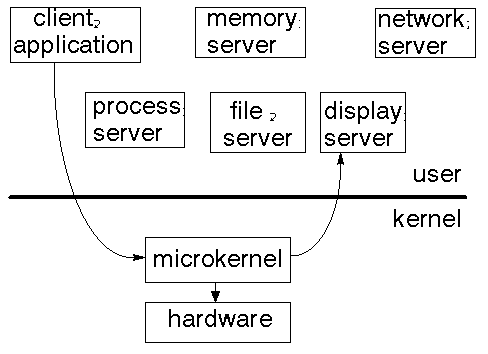
This has become popular recently. It reduces the size of the kernel down to a micro-kernel. For example, with the Mach system teh micro-kernel only looks after htread scheduling, message passing, virtual memory and device drivers. Everything else runs in user mode.
C Coding Standard
These are based on the Indian Hill style guide.
Preamble
The beginning of each file should have a header giving the purpose of the file,
author, filename. It may also include things like version numbers, etc.
This is from xmfm:
/*************************************************
* File: $Source: main.c,v $
* Author: Jan Newmarch
* Last modified: $Date: 1993/04/01 04:15 $
* Version: $Revision: 1.11 $
* Purpose: This file contains the main routine
* It sets up the geometry and calls the
* Xt main loop.
*
* Revision history:
* 16 Oct 92 caddr_t changed to XtPointer
* 3 Nov 92 lint-ed
* 21 Nov 92 added icon pixmap
* 3 Dec 92 added widget argument to
* ErrorDialog
* 18 Dec 92 cleaned compile under g++
* 25 Mar 93 all pointer vbls grounded
* on definition
************************************************/ /
This is from tcl
/*
* tclEnv.c --
*
* Tcl support for environment
* variables, including a setenv
* procedure.
*
*/
#ifndef lint
static char rcsid[] =
"$Header: tclEnv.c,\
v 1.7 91/09/23 11:22:21\
ouster Exp $ SPRITE (Berkeley)";
#endif /* not lint */
Function declaration
There should be a comment that gives a short description of what the function
does and (if not clear) how to use it. Discussion of non-trivial design decisions
and side-effects is also appropriate.
This is from xmfm:
/*************************************************
* Function: fatal()
* Purpose: report a fatal error and giveup
* In parameters: s
* Out parameters:
* Precondition: error of some kind occurred
* that cant be fixed
* Postcondition: application stopped after
* message printed to stderr
*************************************************/
This is from tcl:
/*
*---------------------------------
*
* unsetenv --
*
* Remove an environment variable,
* updating the "env" arrays
* in all interpreters managed by us.
*
* Results:
* None.
*
* Side effects:
* Interpreters are updated, as is environ.
*
*---------------------------------
*/
Inline comments
Comments should describe what is happening, how it is being done, what parameters
mean, which globals are used and which are modified and any restrictions or
bugs. Comments have to be maintained:
When the code and the comments disagree, both are probably wrong.
Indentation
You should indent using the block structure of the program. I usually use 4
spaces per indent. You should leave blank lines between separate parts. The
intention is to make the program readable.
Consistency
Whatever style you use, be consistent. It may be relatively easy to maintain
a program with a consistent style, virtually imposssible without it.
This page is
http://pandonia.canberra.edu.au/OS/l7_2.html,
copyright Jan Newmarch.
It is maintained by Jan Newmarch.
email:
jan@ise.canberra.edu.au
Web:
http://pandonia.canberra.edu.au/
Last modified: 26 June, 1995