Introduction
This lecture looks at memory management by programs, and simple schemes
used by the O/S. It considers both the API and various ways of
implementing such APIs.
Reference: Tanenbaum Chapter 3
Memory management within a program
A program starts with an amount of memory allocated for use by it. The program
will use this memory in two ways:
- through procedure calls
- through dynamic data types
When a procedure is called, information about the call is placed on the user
stack. Space for local variables is also allocated on the user stack. This
is organised as a stack which grows when a procedure is called and shrinks
when a procedure exits.
When dynamic memory is required it is taken from the ``heap''. Operations on
the heap include
- get memory from heap
- release memory to heap
- exchange memory for a different bit
Standard C API
#include <stdlib.h>
void *malloc(size_t size);
void free(void *ptr);
void *realloc(void *ptr,
size_t size);
Given a dynamic list structure
typedef struct list_elmt {
int elmt;
struct list_elmt *next;
} list_elmt, *listptr;
This creates a new node:
listptr new_node(int n)
{
listptr p;
p = (listptr) malloc(
sizeof(struct list_elmt));
if (p == NULL) {
fprintf(stderr,
"out of space\n");
return NULL;
}
p->elmt = n;
p->next = NULL;
return p;
}
This releases all memory in the list back to the heap;
free_list(listptr p)
{
listptr q;
while (p != NULL) {
q = p->next;
free(p);
p = q;
}
}
Sometimes you want to use an array, but its size may need to be determined
on the fly:
Implementation
The heap will consist of space some of which is in use and some of which is
free.
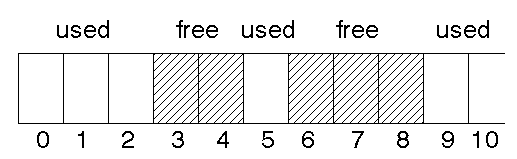
This is just one example of the general memory management problem, whether
it is memory managed by a program, memory managed by the O/S (which is a program),
disk space, etc. One method of keeping track is by a bitmap (as mentioned in
file system management). More common is by linked list.
There may be one linked list containing both used and free memory:
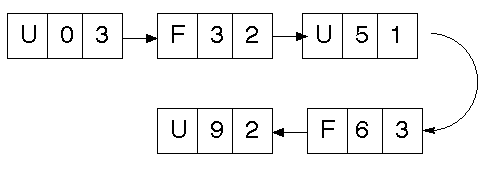
There may be two lists, one for used space, one for free:
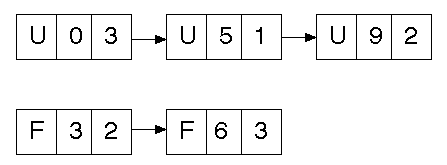
The lists may be ordered on address (as above) or by size:
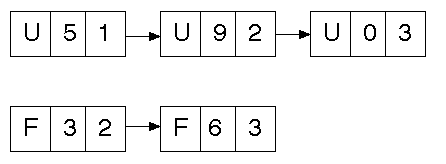
If a separate free list is used, it may be implemented directly in the free
space:
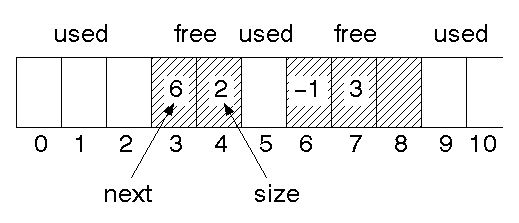
When a request is made for a piece of memory, it can be taken from the free
list in a number of ways:
First fit
This finds the first hole in the list big enough for the request. This is fast
to do in an address sorted list, because it just traverses the list until it
finds a large enough one.
Best fit
This finds the smallest hole in the list big enough for the request. Surprisingly,
best fit is not always the best method, because it results in lots of tiny
leftover pieces that are not large enough to be used. This is fast to do in
a size sorted list.
Worst fit
This finds the largest hole in the list. This is fast in a size sorted list,
if the largest is first. This is not so good either.
Returning memory
When a piece of memory is returned to the free list, it is not just added to
the list - if there is already memory on this list either side of it then the
pieces should be coalesced into one. This is easy to do in an address sorted
list.
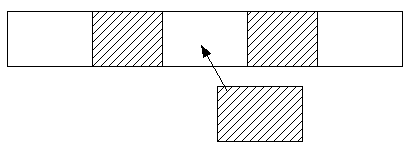
Buddy system
This uses a trick on the way numbers are stored - in binary. In this system,
memory is only allocated in units that are powers of two. So if 3 bytes are
requested you get 4, and if 129 bytes are requested you get 256. This does
lead to wasted space (internal fragmentation).
A list of lists of free space is maintained. The first list is the 1 byte blocks,
the second the 2 byte blocks, then the 4 byte blocks, etc. When a request is
made, the size is rounded up and a search made of the appropriate list. If
there is something there it is allocated. If not, a search is made of the next
largest, and so on until a block is found that can be used. This search can
be done quickly.
A block that is too large is split into two. Each part is known as the ``buddy''
of the other. When it is split, it is taken off the free list for its size.
One buddy is placed on the free list for the next size down, and the other
is used, splitting it again if needed.
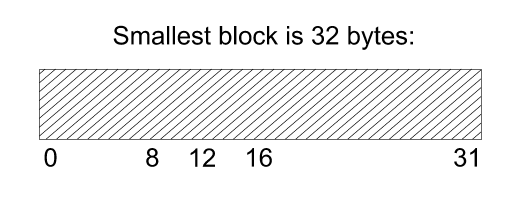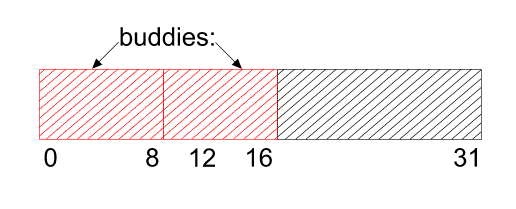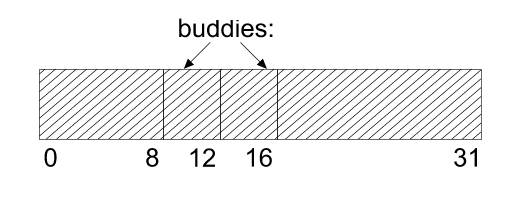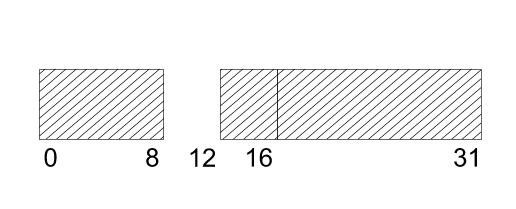
For example, suppose a request is made for a 3 byte piece of memory and the
smallest free block is 32 bytes. It is split into two 16 byte buddies, one
of which is placed on the 16 byte free list. The other is split into two 8
byte buddies, one of which is placed on the 8 byte list. The other is split
into two 4 byte buddies, one of which is placed on the 4 byte free list, and
the other - finally - is used.
When a piece of memory is released, it is placed back on the appropriate free
list. Here now is the trick: two free blocks can only be combined if they are
buddies, and buddies have addresses that differ only in 1 bit. Two 1 byte blocks
are buddies iff they differ in the last bit, two 2 byte blocks are buddies
iff they differ in the 2nd bit,and so on. So it is very quick to find out if
two blocks can be combined.
The advantage of the buddy system is that granting and returning memory are
both fast operations. The disadvantage is internal fragmentation.
Compaction
Eventually, memory will become ``externally fragmented''. That is there will
be lots of small pieces of memory on the free list(s) that are too small to
be useful. When a request comes in for something larger than any of these it
will fail even though there may be enough free space in total.
To avoid this happening, memory must be compacted every now and then. This
means, say, moving all blocks down to the low end of memory to leave space
at the top as one large block. Everything that references the old memory blocks
will of course now be pointing to the wrong place. Various code relocation
techniques done in CO2 help here.
Simple O/S memory management
The above was general memory management for any situation. Now we look at what
the O/S in particular has to do. It has to manage processes. When a process
starts, it must allocate a chunk of memory for it to run in. When it terminates,
it returns that chunk to free space. Here are some simple schemes.
No allocation
Nothing is done by the O/S. A process has access to all memory and can do what
it wants. This is only found on very early machines. In these machines, every
program had to do its own I/O, etc, and had to reload the O/S on termination.
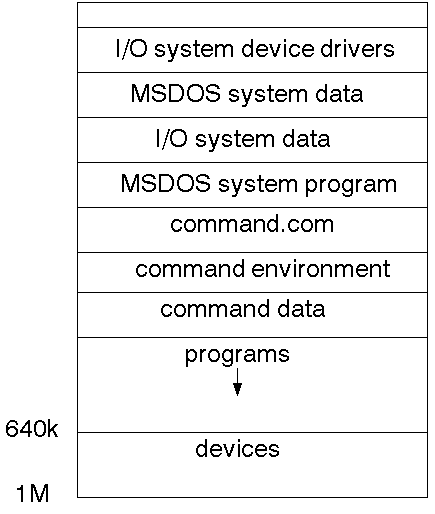
Single user
In this system, the O/S reserves a section for itself, and a process can access
the rest. This is the scheme used by MSDOS. Due to a lack of memory protection,
a misbehaved MSDOS program can in fact overwrite the O/S. Normally, when MSDOS
loads a program it sets aside space for it using information in the header
part of an EXE file. The program then asks for memory from MSDOS using the
ALLOC_MEMORY system call and releases it back to MSDOS using FREE_ALLLOCATED_MEM.
Mulitprogramming
In a multitasking system, many processes will be attempting to use the CPU
and memory. It is not possible to just run each of them to conclusion, because
for an interactive program (say a shell) this may be for many hours. In addition,
while a process is waiting on an input or output device it generally cannot
do anything else and so will be idle.
One scheme is to load a number of processes into different parts of memory,
and let them use the CPU according to some scheme (see process management later
this course).
The processes could be loaded using a static scheme in which each one gets
a fixed size piece of memory, and cannot get more. This was once used in the
IBM 360, in which programs would be loaded into fixed size partitions.
With a dynamic memory scheme, processes can ask for more memory as they need
it. This can then be given if available from the free list maintained by the
O/S.
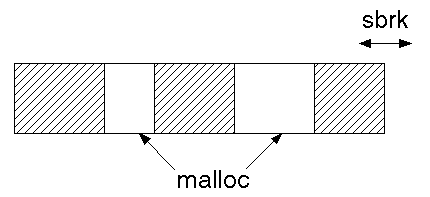
In Unix, processes have their memory requirements divided up into several parts:
text (program code), stack and data areas. The data area is allowed to grow
or shrink using the brk or sbrk
system calls. Within a data area the process
itself manages its area using the standard C library calls malloc, free and
realloc. These calls themselves make use of brk and sbrk if they need to change
the size of the data area. This is a two-level mechanism.
This page is
http://pandonia.canberra.edu.au/OS/l7_1.html,
copyright Jan Newmarch.
It is maintained by Jan Newmarch.
email:
jan@ise.canberra.edu.au
Web:
http://pandonia.canberra.edu.au/
Last modified: 26 June, 1995