Introduction
This lecture looks at filesystems from the O/S viewpoint.
It covers file operations in general, and the Unix API
(Application Programmer's Interface) for these.
Choices in how a file system can be implemented are examined,
and how the Unix file system is done.
File Systems
We have already done many things from the users viewpoint, such as file naming,
directory structure, file permissions, etc, using Unix and MSDOS as primary
examples. Now we look at such things from the O/S viewpoint:
- the O/S view of file systems
- how these can be implemented
- what is a typical API for file services
Structure
Files may be organised as a
- sequence of bytes
- a sequence of records
- a tree
MSDOS and Unix both treat files as byte sequences and impose no internal structure
on them. Individual applications may require an internal structure, but not
the O/S.
Many old systems that used to read 80 column cards use an 80 character record
structure (eg the Burroughs A9)
Some mainframe systems use a tree organisation for files, where each node is
indexed by a key.
Types
The types of file under Unix may be
- regular
- directory
- character special
- block special
Regular files are binary or Ascii files, and contain compiled programs, data
files, source code, text, etc. These are the ``ordinary'' files.
Directory files are used by the O/S to maintain the hierarchical file system.
Character special files are devices at a fixed location,
with volatile contents.
Reads from such files are actually reads from the device. No random access
is available on such files. Examples are keyboard, mouse etc. In Unix, these
are /dev/kbd, /dev/mouse, /dev/audio, etc
Block special files are also devices, but which allow random access. Examples
are SCSI disks /dev/sd0, etc, memory /dev/kmem and floppy disks /dev/fd0
Access
Access to files may be sequential, random or both. It depends on the file type
and support from the O/S. Most regular files allow both.
File operations
The set of operations allowed on files may include
- create
- delete
- open
- close
- read
- write
- append
- seek
- get attributes (security)
- set attributes (security)
- rename
Unix low-level file operations
The stdio library has a high-level interface to the file operations, with printf,
putchar, etc. These are built from a lower-level interface. Typical calls from
this are
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int creat(char *path,
mode_t mode);
int open(char *path,
int oflag,
...);
int close(int fildes);
int read(int fildes,
char *buf,
unsigned nbyte);
int write(int fildes,
char *buf,
unsigned nbyte);
int chmod(char *path,
mode_t mode);
int stat(char *path,
struct stat *buf);
creat takes the pathname of a file and creates a new file, removing the contents
if it already existed. The mode sets the access permissions. This is a bit-wise
OR of the file permissions:
S_IRUSR 0400
S_IWUSR 0200
S_IXUSR 0100
S_IRGRP 040
S_IWGRP 020
S_IXGRP 010
S_IROTH 04
S_IWOTH 02
S_IXOTH 01
This follows the rwx for user, group and other that is shown by ``ls -l''.
The open call opens the file in the mode given by oflag, and returns a file
descriptor. This is an integer which the O/S uses to index into a per process
file descriptor table, which is used to keep info about open files. Zero is
always stdin, 1 is stdout, 2 is stderr.
oflag is a bit-wise OR of a number of constants
O_RDONLY
O_WRONLY
O_CREAT
O_TRUNC
When O_CREAT is one of these flags, an additional argument to open is the file
permission mode.
The read call is a block read of a given number of bytes. This could be tuned
to the physical characteristics of the device read from, for example.
For example, it may be much faster to do a block read of 1024 bytes from
a hard disk than to do 1024 reads of 1 byte from the disk.
The value returned is the actual number of bytes read.
This may be less than the number asked for. For example
-
if you ask for
1024 bytes to be read from a file that only has 53 bytes in it, you will
only get 53.
- input from the keyboard is normally
line-buffered, so no matter how many you ask for, you will only get a
line at a time.
-
a pipeline is often implemented with a buffer size of 4k. Reads
of more than that may cause the pipeline buffer to be filled and emptied
several times.
``read'' returns zero on EOF, and -1 on error. A while loop to read using
this call should always test the return value for > 0:
while ((nread = read(...)) > 0)
...
if (nread == 0)
/* EOF code */
else
/* error code */
The write call is also a block write of a number of bytes. It returns -1 if
a write error occurs (such as no space left).
Example
This is a simple version of cp, using the low-level I/O.
When should you use these low-level functions? Only when you have to.
In general
use the high-level functions. There will be many times when we can't.
Note
that these functions are specific to the Unix API, and are not in Microsoft
C, for example. So code written using these functions will only be portable
across Unix, not to other Operating Systems.
Allocation
Files can be laid out on the disk in a variety of ways
- contiguous
- linked list
- index
- inodes
Contiguous
In a contiguous layout, the entire file is laid out as one sequence of disk
blocks. It is easy to keep track of the file, because you only need its starting
block and size. It means that space must be pre-allocated for the file before
writing it can take place.
Linked list
In a linked list layout, the file is divided into blocks and part of each block
is a pointer to the next block. Keeping track of each file is also easy, because
you only need the start of each list. Sequential access is easy. Random access
is hard. Because space is used by the pointer, reads should not be in powers
of 2.
Index
In an index method, a table is maintained of each block of the disk. Entries
in this table for each index are the value of the next index for a file. Thus
a file starting in block 4 and using blocks 6 and 2 would have table entries
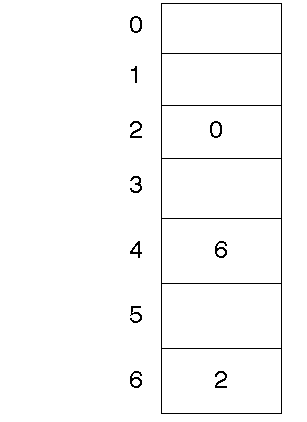

Then you can store the start of the file somewhere else. This makes it easier
to find where a file is, because the index table can be stored in fast memory
instead of on disk, and actual data can be full blocks.
MSDOS uses this system. The root directory is at a fixed location on the disk,
and is contiguous of fixed size.
(This is why you cannot have an unlimited number of files in the root
directory in MSDOS.)
Entries in this for the start of each file
in the root directory point to the FAT (File Allocation Table) which is the
index table for the rest of the disk.
When a new file is created or extended, new blocks can be found by looking
through the FAT for unused entries.
Inodes
The last method uses a fixed size table of inodes . Each entry in the table
contains a set of pointers. These point to the first, second, ... blocks of
the file. This allows direct indexing of a fixed number of blocks. If the file
is bigger than that, then the next entries are to a single indirect block,
to a double indirect block and to a triple indirect block.
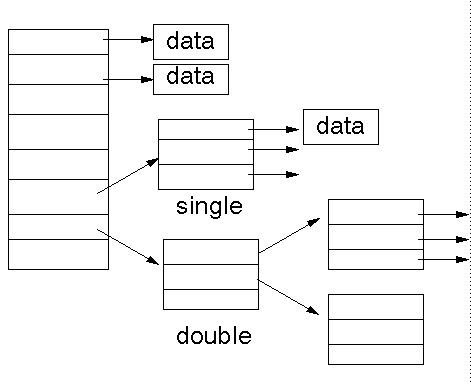
The advantages are that there is quick access to the first blocks,
and potentially
huge file sizes. This method is used by Unix.
The inode is used to store all information about a file,
and there is one inode
per file. This information includes: owner, time last modified,
time last accessed,
size, file permisssions, number of links, etc.
For example, Minix is a simple version of Unix, and Linux has the option
to use a Minix file system. A Minix inode is defined by
struct minix_inode {
unsigned short i_mode;
unsigned short i_uid;
unsigned long i_size;
unsigned long i_time;
unsigned char i_gid;
unsigned char i_nlinks;
unsigned short i_zone[9];
};
This has 7 direct blocks and 2 levels of indirect block.
When a new file is created (by creat), it creates a new
inode entry in the inode table.
Free list
When a file grows, it will fill up any blocks that it currently has, and then
will have to request a new block. Unused or spare blocks will need to be maintained
using a free list. For example, in MSDOS the free list is just those entries
in the FAT table that are unused. Unix keeps a separate free list.
One method of keeping the free list is as a linked list. Traversal of this
may be slow, and it takes up space. Another method (used for small computers)
is a bit vector. In this, the first block is represented by bit 1, the second
by bit 2, etc. A block is free if its corresponding bit is zero, not free otherwise.
Special hardware instructions may support quick perusal of this vector.
The simplest way of allocating a block from this list is FCFS (first come first
served), but other algorithms are possible. For example, since directories
are accessed very frequently, placing blocks for them close to the middle of
the disk may speed up access to them.
Disk caching
Files are located at blocks, and read by blocks. A ``block'' will have its
size determined by hardware and software characteristics. For example, it may
be related to the sector size of the disk. Since a file uses at least one block,
small block sizes are desirable, but since they have to be read from and written
to disk, large sizes are desirable. For example, most Unix systems now use
1kb blocks.
It is becoming increasingly common to reduce the amount of disk access required
by caching. In this a copy of something is kept in fast memory rather than
on disk. For example, a block may be read into memory. If another read is required
from the block, then instead of re-reading it from disk, the read is taken
from a copy of the block in RAM.
The high level I/O functions are often implemented using a cache or buffer.
When a read is first requested, say by getchar, a block is read into an input
cache for that file, Successive getchar's are from this buffer until it becomes
empty, at which point another block-read is done. This block read is tuned
to the disk.
Caching may be of read-only data, such as compiled program code. The cache
size should be big enough that a substantial amount of execution is done using
just the code in the cache.
When data is changed, caching becomes more interesting. Suppose I am modifying
a file, and I make a change. To reduce disk I/O this should be cached locally,
and not written until a lot can be written. Suppose the system crashes or someone-else
wants to make use of the file in the meantime. The caches and disk will be
inconsistent. The simplest solution is a write through cache, so that writes
are reflected immediately on the disk. Of course, this loses some of the potential
savings...
This page is
http://pandonia.canberra.edu.au/OS/l6_1.html,
copyright Jan Newmarch.
It is maintained by Jan Newmarch.
email:
jan@ise.canberra.edu.au
Web:
http://pandonia.canberra.edu.au/
Last modified: 26 August, 1995