Structures are the C equivalent of records. A structure type is defined by
struct struct-name {
type field-name;
type field-name;
...
}
e.g.
struct student_type {
char name[20];
int ID;
}
Elements of that type are defined by
struct student_type fred, bill,
all_students[100];
Because it is tedious to have to remember to use the word ``struct'' in these,
the stucture is often ``typedef''-ed to avoid this:
typedef struct student_type {
char name[20];
int ID;
} student_type;
student_type fred, bill;
You access fields of a structure with the ``.'' notation:
fred.ID = 891234;
strcpy(fred.name, "fred");
It is common to have pointers to structures. The straightforward notation is
clumsy, so a shorthand is available
(*student_ptr).ID = ...
student_ptr->ID = ...
(Note that the student_ptr must be pointing to a valid record!)
Printing the current date. The standard library has a number of time-related
functions. The first is
#include <time.h>
time_t time(time_t *timer)
This returns the current time, in some unspecified format. This can be changed
into a known format by functions such as
#include <time.h>
struct tm *localtime(time_t
*timer)
The structure tm has fields
struct tm {
int tm_sec; /* 0..61 */
int tm_min; /* 0..59 */
int tm_hour;/* 0..23 */
int tm_wday; /* 0..6 */
int tm_mon; /* 0..11 */
...
}
This allows you access to the localtime. For example
int current_day(void)
{ struct tm *local;
time_t t;
t = time(NULL);
local = localtime(&t);
return local->tm_wday;
}
Example:
Structures can be recursive, as in lists or trees.
You need to use pointers
inside the data structure. Some dynamic list functions:
typedef struct list {
int elmt;
struct list *next;
} list_elmt, *list_ptr;
list_ptr new_elmt(int n)
{ list_ptr p;
p = (list_ptr) malloc(
sizeof(list_elmt));
if (p != NULL) {
p->elmt = n;
p->next = NULL;
}
return p;
}
void print_list(list_ptr p)
{
while (p != NULL) {
printf(" %d", p->elmt);
p = p->next;
}
}
list_ptr make_list(void)
{ /* create a list storing 0..9
(or as much of it as
possible).
*/
list_ptr start_list, p;
int n;
start_list = p = new_elmt(0);
if (p == NULL)
return NULL;
for (n = 1; n < 10; n++) {
p->next = new_elmt(n);
if (p->next == NULL)
break;
p = p->next;
}
return start_list;
}
Preprocessor
The first stage of compilation is to pass the source through the preprocessor.
This expands out certain symbols and produces another C source file (that you
do not normally see).
Include files
The statement
#include file
reads in the contents of the file at that point. These should be specification
files, giving details of data-types, function definitions, etc. The filename
can either be enclosed in double quotes "..." or in brackets <...>
#include "myspec.h"
#include <stdio.h>
names in quotes normally refer to header files in your current directory, names
in brackets refer to files located in a standard place (usually /usr/include
on Unix).
Defines
If a piece of text is #define'd, then whenever that piece of text is encountered,
the remainder of the line following is substituted for it
#define MAX_SIZE 10
#define WARNING \
printf("Warning!!!\n");
if (x == 0)
WARNING
If the thing being defined has parameters then they act as a macro and parameter
subsitution is performed
#define SUM(x, y) x + y
a = SUM(b, c);
Macros are useful, but they can be a source of obscure errors:
a = SUM(b, c) * d;
becomes
a = b + c * d
Prevent this (and similar things) by enclosing everything in brackets
#define SUM(x, y) ((x) + (y))
Macros that use their arguments more than once can go wrong when used in situations
with side-effects:
#define islower(x) \
((ch) >= 'a' && \
(ch) <= 'z')
if (islower(getchar())) ...
Conditional compilation
The ifdef construct allows the preprocessor to keep or omit pieces of code.
I often have this:
#define DEBUG
#ifdef DEBUG
printf("Reached this bit\n");
#endif
Multiple files
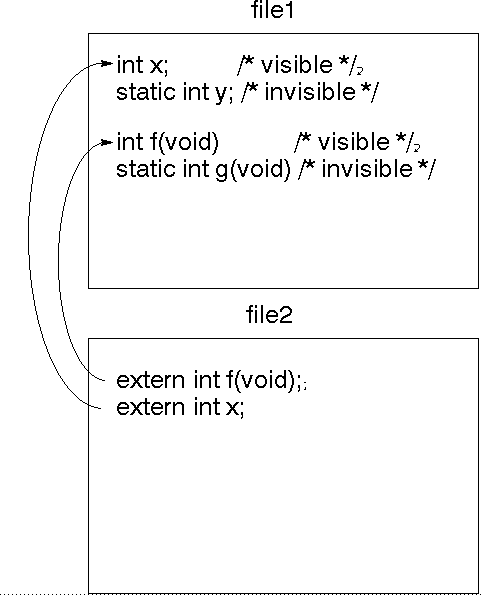
A C program can be across many files.
When a variable or function is declared static, it is not visible outside of
its own file. This allows functions to be grouped together as a ``package''.
Here is a simple stack package:
#define SIZE 10
static int TOS = 0;
static stack[SIZE];
int push(int n)
{
if (TOS == SIZE - 1)
/* full up, return false */
return 0;
stack[TOS++] = n;
return 1;
}
int pop(int *n)
{
if (TOS == 0)
return 0;
*n = stack[--TOS];
return 1;
}
For completeness, this should have a specification file ``stack.h'' containing
extern int push(int n);
extern int pop(int *n);
Multiple files can be compiled all at once by placing them all on the command
line:
gcc -o prog src1.c src2.c ...
Make
There are smarter methods to avoid unneccessary compilations, which avoid
having to compile all the source files at once. By hand, a smarter method
of compiling three files to make one executable is
gcc -c src1.c
gcc -c src2.c
gcc -c src3.c
gcc -o prog src1.o src2.o src3.o
When any one of the files changes, only one of the three ``conditional''
compiles has to be repeated, plus the final link compile.
This can be automated using the ``make'' command. This expects a file
``Makefile'' which contains dependency instructions. These are of the
form
file : files it depends upon
<tab> instructions to bring it up to date
For example
OBJS = src1.o src2.o src3.o
CFLAGS = -g
src1.o : src1.c
gcc -c $(CFLAGS) src1.c
src2.o : src2.c
gcc -c $(CFLAGS) src2.c
src3.o : src3.c
gcc -c $(CFLAGS) src3.c
prog : $(OBJS)
gcc -o prog $(CFLAGS) $(OBJS)
Then whenever you make a change, running ``make'' automatically figures
out which commands to run.
make has inbuilt rules about many things, including how to compile C files.
The above can be abbreviated to
UNAME(2V) SYSTEM CALLS UNAME(2V)
NAME
uname - get information about current system
SYNOPSIS
#include
int uname (name)
struct utsname *name;
DESCRIPTION
uname() stores information identifying
the current operating system in the
structure pointed to by name.
uname() uses the structure defined in
, the members of which
are:
struct utsname {
char sysname[9];
char nodename[9];
char nodeext[65-9];
char release[9];
char version[9];
char machine[9];
}
uname() places a null-terminated character
string naming the current operating
system in the character array sysname;
this string is SunOS on Sun systems.
nodename is set to the name that the
system is known by on a communications
network; this is the same value as is
returned by gethostname(2). release
and version are set to values that further
identify the operating system.
machine is set to a standard name that
identifies the hardware on which the
SunOS system is running. This is the same
as the value displayed by arch(1).
RETURN VALUES
uname() returns:
0 on success.
-1 on failure.
SEE ALSO
arch(1), uname(1), gethostname(2)
This doco defines the header file to use and the calling syntax of the function
(note that it uses ``old style'' C syntax in which the parameter types are
listed after the function).
The description shows what the structure is. If you aren't told it, then you
probably don't need to know it. The return values are shown generally indicating
success or fail. The See Also points you to other relevant functions. From
this we can write
This page is
http://pandonia.canberra.edu.au/OS/l5_2.html,
copyright Jan Newmarch.
It is maintained by Jan Newmarch.
email:
jan@ise.canberra.edu.au
Web:
http://pandonia.canberra.edu.au/
Last modified: 14 August, 1995