The imperative languages use the procedure as a means of structuring the language.
The language will have conditionals, loops and procedure calls.
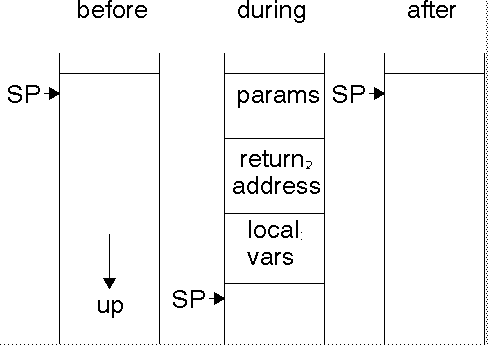
When a procedure is called, it usually makes use of the stack, pushing parameters
onto the stack and reserving space for local variables:
Parameter types
Value parameters
When a parameter is called by value, the actual value of the parameter is placed
on the stack. This can then be used and modified by the procedure without any
change to any original variable.
Reference parameters
The address of the parameter is passed into the procedure. Any use of the parameter
within the procedure uses the address to access/change the value.
C does not have call by reference, but only call by value. Most other procedural
languages have both.
Remote procedure call
The socket method of network use is a message-based system, in which one process
writes a message to another. This is a long way from the procedural model.
The remote procedure call is intended to act like a procedure call, but to
act across the network transparently.
The process makes a remote procedure call by pushing its parameters and a return
address onto the stack, and jumping to the start of the procedure. The procedure
itself is responsible for accessing and using the network.
After the remote execution is over, the procedure jumps back to the return
address. The calling process then continues.
Without RPC
Consider how you would implement a procedure to find the time on a remote machine
as a string, using the IP socket calls:
int remote_time(char *machine,
char *time_buf)
{ struct sockaddr_in serv_addr;
int sockfd;
int nread;
if (sockfd =
socket(AF_INET,
SOCK_STREAM, 0))
< 0)
return 1;
serv_addr.sin_family =
AF_INET;
serv_addr.sin_addr.s_addr =
inet_addr(machine);
serv_addr.sin_port =
htons(13);
if (connect(sockfd,
&serv_addr,
sizeof(serv_addr))
< 0)
return 2;
nread = read(sockfd,
time_buf,
sizeof(time_buf));
time_buf[nread] = '\0';
close(sockfd);
return 0;
}
This very obviously uses the network.
What RPC should look like?
The network needs to be made invisible, so that everything looks just like
ordinary procedure calls. The calling process would execute
remote_time(machine, time_buf);
All networking should be done by the RPC implementation, such as connecting
to the remote machine. On the remote machine this simple function gets executed:
int remote_time(char *time_buf)
{ struct tm *time;
time_t t;
time(&t);
time = localtime(&t);
strcpy(time_buf,
asctime(time));
return 0;
}
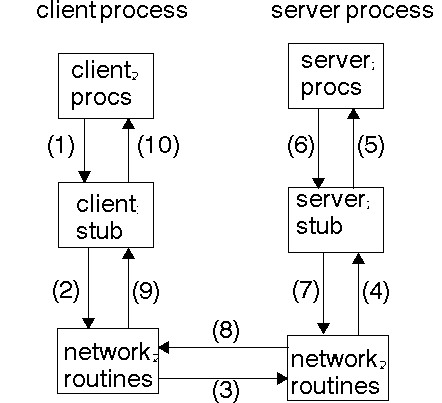
Stubs
When the calling process calls a procedure, the action performed by that procedure
will not be the actual code as written, but code that begins network communication.
It has to conenct to the remote machine, send all the parameters down to it,
wait for replies, do the right thing to the stack and return. This is the client
side stub.
The server side stub has to wait for messages asking for a procedure to run.
It has to read the parameters, and present them in a suitable form to execute
the procedure locally. After execution,it has to send the results back to the
calling process.
The client calls the local stub procedure. The stub packages up the parameters
into a network message. This is called marshalling.
Networking functions in the O/S kernel are called by the stub to send the message.
The kernel sends the message(s) to the remote system. This may be connection-oriented
or connectionless.
A server stub unmarshals the arguments from the network message.
The server stub executes a local procedure call.
The procedure completes, returning execution to the server stub.
The server stub marshals the return values into a network message.
The return messages are sent back.
The client stub reads the messages using the network functions.
The message is unmarshalled. and the return values are set on the stack for
the local process.
Data representation
A procedure, for example, may have a short int, a string and an ordinary int
as parameters. How is it to be marshalled so that it can be correctly unmarshalled
at the other end?
For example, the short int could use the first two bytes with the next two
blank, or the other way round. The string could be prefixed by its length or
be terminated by a sentinel value. If the length is sent, should it be an int?
A short int? The ordinary int could be big-endian or little-endian.
The Sun RPC uses a standard format called XDR. The ordering is big-endian and
the minimum size of any field is 32 bits. DCE uses a different format, as does
Xerox Courier.
The message could be formed using implicit typing. That is, only the values
are sent, and it is assumed that both the client and the server know what the
types are meant to be.
Alternatively, there is a type specification ISO language called ASN.1 (Abstract
Syntax Notation). This increases message sizes, but is more reliable.
Valid data types
Can you send a pointer value to a remote procedure?
A pointer would refer to an address in the calling procedure's address space.
The remote procedure could not assign a meaning to this as it would not have
access to that address space. So passing pointers is usually not possible.
How about fixed size arrays? Variable sized arrays? Variant records? Floating
point numbers?
Each RPC method must have a list of acceptable data types that can be passed
across the network.
Generating stubs
Common RPC methods use implicit typing. This means that both the server stub
and the client stub must agree exactly on what the parameter types are for
any remote call.
If this was done by hand, then obscure errors would result. So it must be done
automatically.
For a normal procedure call, the compiler is able to look at the specification
of the procedure and do two things: generate the correct code for placing arguments
on the stack when a procedure is called, and generate correct code for using
these parameters within the procedure.
In RPC, this is more complex. The compiler must generate separate stubs, one
for the client stub embedded in the application, and one for the server stub
for the remote machine.
The compiler must know which parameters are in parameters and which are out.
In parameters are sent from the client to server, out parameters are sent back.
Languages like C have no concept of in or out parameters. Therefore the compiler
cannot be a standard C compiler, and the specification of the procedures cannot
be done in C.
A typical specification might be
int max(in int x,
in int y,
out int z);
A stub compiler would use this to generate the two stubs.
Errors
An ordinary procedure may cause an error by executing an illegal instruction
such as divide by zero or illegal memory reference.
What errors can occur in a remote procedure call?
Can't find the server
If the server is not there, an error indication should be returned.
In C, it may be possible to return an error value for some functions, but not
for all. Anyway, in Ada, if you have to use a function then you can't use the
parameters like you can with procedures.
In Ada you can raise an exception, or in C generate a signal. However, Pascal
has neither of these concepts.
There is no language-independant solution.
Request to server is lost
This is easy: the client stub sets a timer that expires if no reply is received.
Send the message again.
Unfortunately, what if the server has in fact received the message, but is
just being slow. The request may end up being executed twice or more. This
can be avoided by including an identifier in the message to stop it being retried
if it has already been received.
Reply from server is lost
This is the same type of problem.
Server crashes
In this case, when the server comes back up, it will probably have no record
of having received the message, and will probably do it again. This can be
okay. If the message was a funds transfer message then it probably won't be.
Preventing this is the at most once problem.
One solution is to not resend messages. In this case you hit the at least once
problem.
Client crashes
This can be guarded against be keeping a record on disk of each RPC message
sent. This slows things down a bit though.
Sun RPC
This is a common RPC mechanism, available on lots of platforms.
it consists of a data representation, a set of low-level calls to
execute the procedure remotely, and a higher-level mechanism using
a program rpcgen to gnerate much of the networking code
from a specification file.
XDR
Valid data types supported by XDR include
int
unsigned int
long
structure
fixed array
string (null terminated char *)
binary encoded data (for other data types such as lists)
RPC specification
A file with a ``.x'' suffix acts as a remote procedure specification file.
It defines functions that will be remotely executed functions.
Functions are restricted: they may take at most one in
parameter, and return at most one out parameter as the
function result.
If you want to use more than one in parameter,
you have to wrap them up
in a single structure, and similarly with the out values.
Multiple functions may be defined at once. They are numbered
from one upwards, and any of these may be remotely executed.
The specification defines a program that will run remotely, made up
of the functions. The program has a name, a version number and a unique
identifying number (chosen by you).
For example, a program may have two local functions to find the date on a
machine. The local definitions could be
long bin_date(void);
char *str_date(long);
The program with these specified as
remote procedures for a remote
machine would define the two functions bin_date and
str_date in file rdate.x:
program RDATE_PROG {
version RDATE_VERS {
long BIN_DATE(void) = 1;
string STR_DATE(long) = 2;
} = 1;
} = 1234567;
Each of these could have one argument.
rpcgen
rpcgen is a program that takes a specification file as command
line parameter and generates C source files that can be used as
client and server stubs.
rpcgen run on rdate.x would generate files
rdate.h - a header file for both client and server sides.
rdate_svc.c - a set of stub functions for use on the server side.
This also defines a full main function that will allow the server
side to run as a server program i.e. it can run and handle requests
across the network.
rdate_clnt.c - a set of stub functions for use on the client side
that handles the remote call.
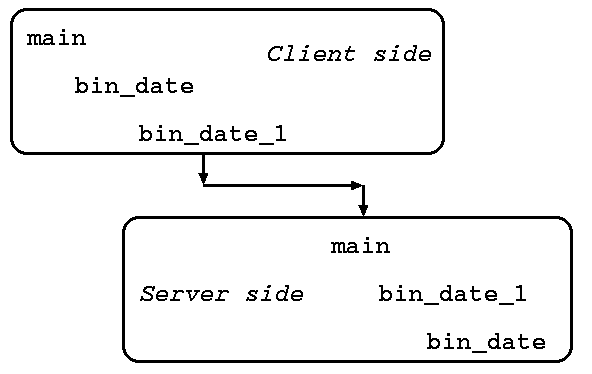
Functions are generated from the specification as follows:
The function name is all lower-case, with ``_1'' appended.
On the client side the function generated has two parameters, on the server
side it has the same number as in the specification.
The client side function has either the one parameter of the spec,
or a dummy void * pointer (use NULL) as first parameter.
On the client side, the second parameter is a ``handle'' created by
the C function clnt_create().
On both sides, the function return value is replaced by a pointer
to that function value.
In this example, the rdate_clnt.c would define
long *bin_date_1(void *, CLIENT *);
char **str_date_1(long *, CLIENT *);
On the server side, rdate_svc.c would define
long *bin_date_1(void *, struct svc_req *);
char **str_date_1(long *, struct svc_req *);
Note that the function returns is in terms of a pointer to the original
data type. You are expected to write versions of the functions which
use a variable to store the pointer value returned, and dereference
this variable.
On the client side this is
extern CLIENT *handle;
long bin_date(void)
{
long *p;
p = bin_date_1(NULL, handle);
return *p;
}
char *str_date(long l)
{
char **p;
p = str_date_1(l, handle);
return *p;
}
On the server side a static variable must be used to ensure that
a valid address is returned. This is
long *bin_date_1(void *p, struct svc_req *r)
{
static long l;
l = bin_date();
return &l;
}
char **str_date_1(long *l, struct svc_req *r)
{
static char *s;
s = str_date(*l);
return &s;
}
Finally, the ``handle'' variable on the client side is set by a call
#define RMACHINE "localhost"
CLIENT *handle;
handle = clnt_create(RMACHINE,
RDATE_PROG,
RDATE_VERS,
"tcp");
which would be added to the main function before any of the rpc calls.
Putting this all together, here is an original, non-RPC program:
if this source is time_clnt.c, the compile command is
gcc -o time_clnt time_clnt.c rdate_clnt.c
On the server side, the reverse must be carried out, to insert the original
contents of the functions back into the RPC stubs:
if this source is time_svc.c, the compile command is
gcc -o time_svc time_svc.c rdate_svc.c
Time Synchronisation
Distributed time
In a single computer there is only one clock, and usually only one CPU. It
is easy to synchronize processes, because they can examine the clock.
For example, a process can run at a regular time each day by waking up, examining
the clock, and going back to sleep if it is too early.
A backup program can examine the ``last backed up'' time and the ``last modified''
time of a file to decide whether or not it has changed since the last backup.
In a distributed system there are many clocks. Each one may have a different
value of the time.
Suppose a backup program compares the last backup time set by its own clock,
with the last modified time as set by the remote clock. The backup may have
been done at 10.00am,and the file may have been modified at 9.50am. Clearly
it does not need to be backed up - unless the second machine has a clock that
is more than 10 minutes slower than the first clock.
Logical clocks
The actual value of the clock is often not important, just the relative times.
You only need to know that a file has been modified after the last backup to
know that it has to be backed up.
Logical clocks are clocks that may or may not have the physically correct time
(to within error). A clock will be ``wrong'' if it is out of synchronisation
with other clocks. Each logical clock has a current time value.
If machine A communicates with machine B, then the time that the message left
A must be before the time that it arrives at B. This is written A < B.
If two actions occur on the same machine, and A is before B according to the
local clock, then again, A < B.
On the other hand, if two actions occur on two different machines,and there
is no communication between them, then neither A < B nor B < A. The events
are concurrent (as far as the logical time is concerned).
It is actually very simple to ensure that any two logical clocks in a system
are synchronised. Firstly, observe that if two processes never communicate
then they are synchronised.
Secondly if machine A sends a message to B then it must arrive after it left
A. So if A includes its own time, then it must arrive at B after this.
If B's time is later anyway, fine. B is synchronised with A for that event.
If B's time is earlier, then B must be slow. B advances its own time to A+1.
It has now synchronised this event.
Similarly, every time two machines communicate they compare send-time to receive-time
and advance any slow clock.